Тази статия ще обсъди как да използвате Elasticsearch multi-get API за извличане на множество JSON документи въз основа на техните идентификатори. Освен това Elasticsearch ви позволява да използвате една заявка за получаване, за да извлечете документите от индекси, като използвате само идентификаторите на документи.
Да проучим.
Синтаксис на заявката
Следва синтаксисът за Elasticsearch multi-get API:
GET /_mget
GET /<индекс>/_mget
Multi-get API поддържа множество индекси, което ви позволява да извличате документите, дори ако те не са в един и същ индекс.
Заявката поддържа следните параметри на пътя:
- <индекс> – Името на индекса, от който да се извлекат документите, както е посочено от техните идентификатори.
Можете също да посочите другите параметри на заявката, както е показано:
- Предпочитание – Дефинира предпочитания възел или фрагмент.
- Реално време – Ако е зададено на true, операцията се извършва в реално време.
- Опресняване – Принуждава операцията да обнови целевите фрагменти, преди да извлече посочените документи.
- Маршрутизиране – Стойност, която се използва за насочване на операциите към конкретен шард.
- Store_fields – Извлича полетата на документа, съхранени в индекс, а не в документа.
- _източник – Булева стойност, която определя дали заявката трябва да върне полето _source или не.
Заявката изисква тялото, което включва следните стойности:
- Документи – Указва документите, които искате да извлечете. Освен това този раздел поддържа следните атрибути:
- _документ за самоличност – Уникален идентификатор на целевия документ.
- _индекс – Индексът, който съдържа целевия документ.
- Маршрутизиране – Ключът за основния шард на документа.
- _източник – Ако е вярно, включва всички полета източник; в противен случай ги изключва.
- _съхранени_полета – Stored_fields, които искате да включите.
- Идентификационни номера – Идентификационните номера на документите, които искате да извлечете.
Пример 1: Извличане на множество документи от един и същи индекс
Следващият пример показва как да използвате Elasticsearch multi-get API за извличане на документи с конкретни идентификатори от индекса на Netflix:
curl -XGET 'http://localhost:9200/netflix/_mget' -H 'kbn-xsrf: докладване' -H 'Тип съдържание: приложение/json' -d'{
'документи': [
{
'_id': 'T3wnVoMBck2AEzXPytlJ'
},
{
'_id': 'W3wnVoMBck2AEzXPytlJ'
}
]
}'
Дадената заявка трябва да извлече документите с посочените идентификатори от индекса на Netflix. Полученият резултат е както е показано:
{'документи': [
{
'_index': 'netflix',
'_id': 'T3wnVoMBck2AEzXPytlJ',
'_Версия 1,
'_seq_no': 0,
'_основен_термин': 1,
'намерено': вярно,
'_източник': {
'продължителност': '90 минути',
'listed_in': 'Документални филми',
'държава': 'Съединени щати',
'date_added': '25 септември 2021 г.',
'show_id': 's1',
'режисьор': 'Кирстен Джонсън',
'release_year': 2020,
'рейтинг': 'PG-13',
'description': 'Докато баща й наближава края на живота си, режисьорът Кирстен Джонсън инсценира смъртта му по изобретателни и комични начини, за да помогне и на двамата да се изправят пред неизбежното.',
'type': 'Филм',
'title': 'Дик Джонсън е мъртъв'
}
},
{
'_index': 'netflix',
'_id': 'W3wnVoMBck2AEzXPytlJ',
'_Версия 1,
'_seq_no': 12,
'_основен_термин': 1,
'намерено': вярно,
'_източник': {
'страна': 'Германия, Чехия',
'show_id': 's13',
'режисьор': 'Кристиан Швохов',
'release_year': 2021,
'рейтинг': 'TV-MA',
'description': 'След като по-голямата част от семейството й е убито при терористичен атентат, една млада жена е подмамена несъзнателно да се присъедини към същата група, която ги е убила.',
'type': 'Филм',
'title': 'Аз съм Карл',
'продължителност': '127 минути',
'listed_in': 'Драми, международни филми',
'акт': 'Луна Ведлер, Янис Нивьонер, Милан Пешел, Един Хасанович, Анна Фиалова, Марлон Боес, Виктор Бокар, Фльор Джефрие, Азиз Диаб, Мелани Фуше, Елизавета Максимова',
'date_added': '23 септември 2021 г.'
}
}
]
}
Можем също да опростим заявката, като поставим идентификаторите на документи в прост масив, както е показано по-долу:
curl -XGET 'http://localhost:9200/netflix/_mget' -H 'kbn-xsrf: докладване' -H 'Тип съдържание: приложение/json' -d'{
'ids': ['T3wnVoMBck2AEzXPytlJ', 'W3wnVoMBck2AEzXPytlJ']
}'
Предишната заявка трябва да извърши подобно действие.
Пример 2: Извличане на документите от множество индекси
В следния пример заявката извлича множество документи от различни индекси, както е показано:
curl -XGET 'http://localhost:9200/_mget' -H 'kbn-xsrf: отчитане' -H 'Тип съдържание: приложение/json' -d'{
'документи': [
{
'_index': 'netflix',
'_id': 'T3wnVoMBck2AEzXPytlJ'
},
{
'_index': 'дисни',
'_id': '8j4wWoMB1yF5VqfaKCE4'
}
]
}'
Полученият резултат е както е показано:

Пример 3: Изключване на конкретни полета
Можем да изключим конкретни полета от дадена заявка с помощта на параметрите source_include и source_exclude.
Пример е както е показано:
curl -XGET 'http://localhost:9200/_mget' -H 'kbn-xsrf: отчитане' -H 'Тип съдържание: приложение/json' -d'{
'документи': [
{
'_index': 'netflix',
'_id': 'T3wnVoMBck2AEzXPytlJ',
'_източник': невярно
},
{
'_index': 'netflix',
'_id': 'T3wnVoMBck2AEzXPytlJ',
'_източник': {
'include': [ 'listed_in', 'release_year', 'title' ],
'exclude': [ 'description', 'type', 'date_added' ]
}
}
]
}'
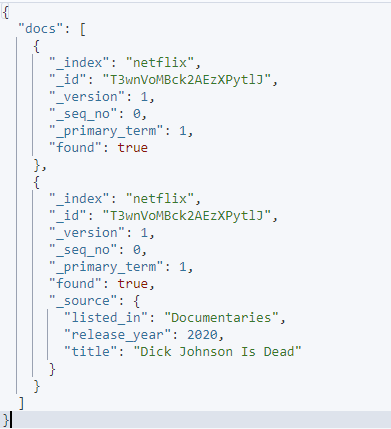
Дадената заявка използва източника за включване и изключване, за да посочи кои полета искате да извлечете в даден документ.
Полученият резултат е както е показано:
Заключение
В тази публикация обсъдихме основите на работата с Elasticsearch multi-get API, който ви позволява да извличате множество документи от различни източници въз основа на техните идентификатори. Чувствайте се свободни да разгледате другите документи за повече информация.
Приятно кодиране!