Бързо очертание
Тази публикация ще демонстрира следното:
- Как да добавите памет към OpenAI Functions Agent в LangChain
- Стъпка 1: Инсталиране на Frameworks
- Стъпка 2: Настройване на среди
- Стъпка 3: Импортиране на библиотеки
- Стъпка 4: Изграждане на база данни
- Стъпка 5: Качване на база данни
- Стъпка 6: Конфигуриране на езиков модел
- Стъпка 7: Добавяне на памет
- Стъпка 8: Инициализиране на агента
- Стъпка 9: Тестване на агента
- Заключение
Как да добавите памет към OpenAI Functions Agent в LangChain?
OpenAI е организация за изкуствен интелект (AI), която е създадена през 2015 г. и в началото е организация с нестопанска цел. Microsoft инвестира много богатства от 2020 г., тъй като обработката на естествен език (NLP) с AI процъфтява с чатботове и езикови модели.
Изграждането на OpenAI агенти позволява на разработчиците да получат по-четливи и точни резултати от интернет. Добавянето на памет към агентите им позволява да разбират по-добре контекста на чата и също да съхраняват предишните разговори в паметта си. За да научите процеса на добавяне на памет към агента за функции на OpenAI в LangChain, просто преминете през следните стъпки:
Стъпка 1: Инсталиране на Frameworks
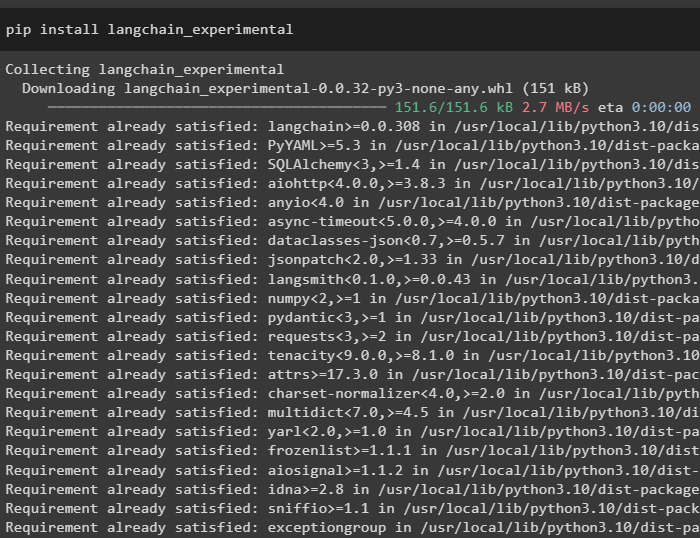
Първо, инсталирайте зависимостите на LangChain от „langchain-експериментален“ рамка с помощта на следния код:
pip инсталирайте langchain - експериментален
Инсталирайте „google-search-results“ модул за получаване на резултатите от търсенето от сървъра на Google:
pip инсталирайте google - Търсене - резултати 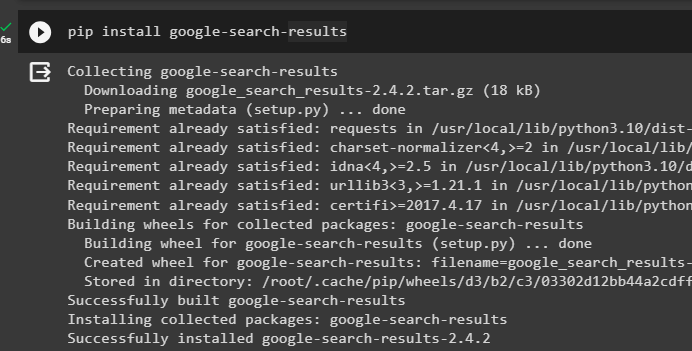
Освен това инсталирайте модула OpenAI, който може да се използва за изграждане на езиковите модели в LangChain:
pip инсталирайте openai 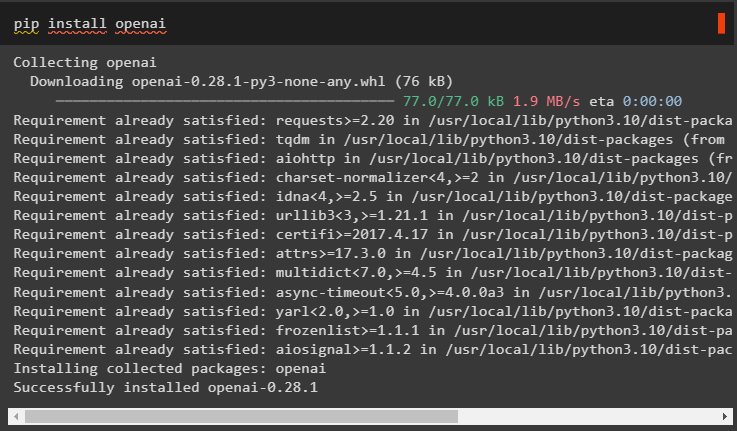
Стъпка 2: Настройване на среди
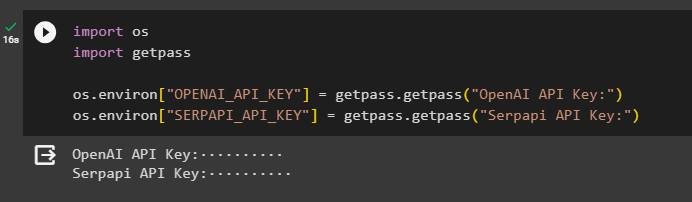
След като получите модулите, настройте среди с помощта на API ключовете от OpenAI и SerpAPi сметки:
импортиране Виеимпортиране getpass
Вие. приблизително [ „OPENAI_API_KEY“ ] = getpass. getpass ( „API ключ на OpenAI:“ )
Вие. приблизително [ „SERPAPI_API_KEY“ ] = getpass. getpass ( „API ключ на Serpapi:“ )
Изпълнете горния код, за да въведете API ключовете за достъп до средата и натиснете enter, за да потвърдите:
Стъпка 3: Импортиране на библиотеки
Сега, когато настройката е завършена, използвайте зависимостите, инсталирани от LangChain, за да импортирате необходимите библиотеки за изграждане на паметта и агентите:
от Langchain. вериги импортиране LLMMathChainот Langchain. llms импортиране OpenAI
#вземете библиотека за търсене от Google в интернет
от Langchain. комунални услуги импортиране SerpAPIWrapper
от Langchain. комунални услуги импортиране SQLDatabase
от langchain_experimental. sql импортиране SQLDatabaseChain
#вземете библиотека за създаване на инструменти за инициализиране на агента
от Langchain. агенти импортиране AgentType , Инструмент , инициализиращ_агент
от Langchain. chat_models импортиране ChatOpenAI
Стъпка 4: Изграждане на база данни
За да продължим с това ръководство, трябва да изградим базата данни и да се свържем с агента, за да извлечем отговори от нея. За да изградите базата данни, е необходимо да изтеглите SQLite, като използвате това ръководство и потвърдете инсталацията, като използвате следната команда:
sqlite3Изпълнение на горната команда в Терминал на Windows показва инсталираната версия на SQLite (3.43.2):
След това просто се насочете към директорията на вашия компютър, където базата данни ще бъде изградена и съхранена:
cd работен плотcd mydb
sqlite3 Chinook. db
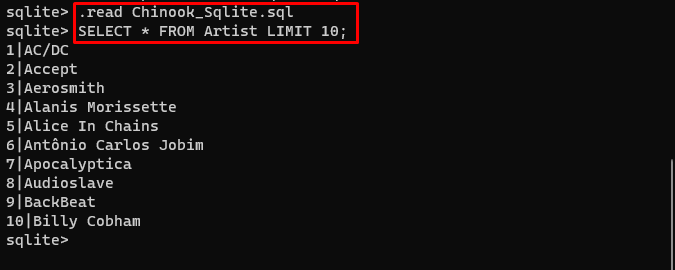
Потребителят може просто да изтегли съдържанието на базата данни от това връзка в директорията и изпълнете следната команда, за да изградите базата данни:
. Прочети Chinook_Sqlite. sqlИЗБЕРЕТЕ * ОТ Изпълнител LIMIT 10 ;
Базата данни е успешно изградена и потребителят може да търси данни от нея чрез различни заявки:
Стъпка 5: Качване на база данни
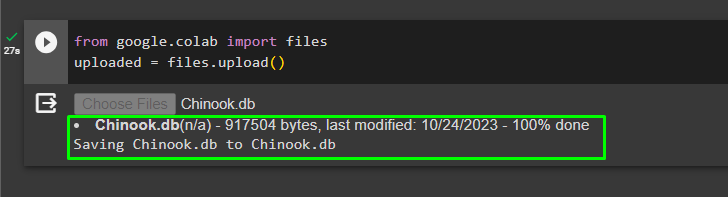
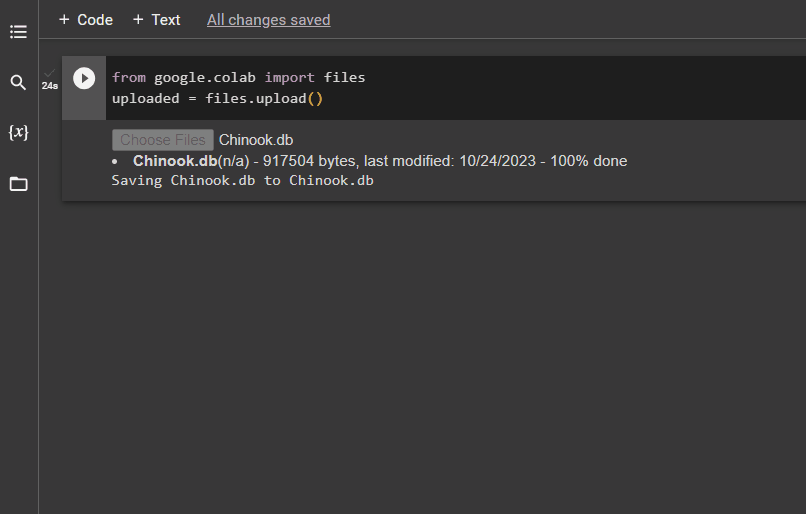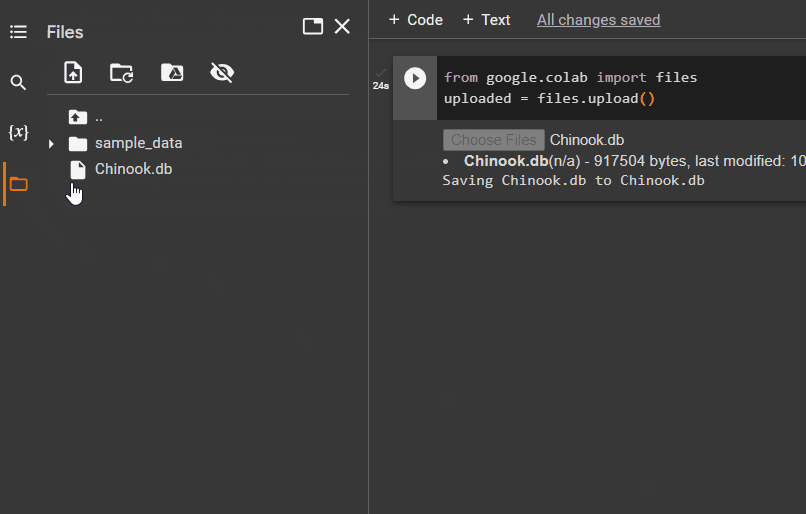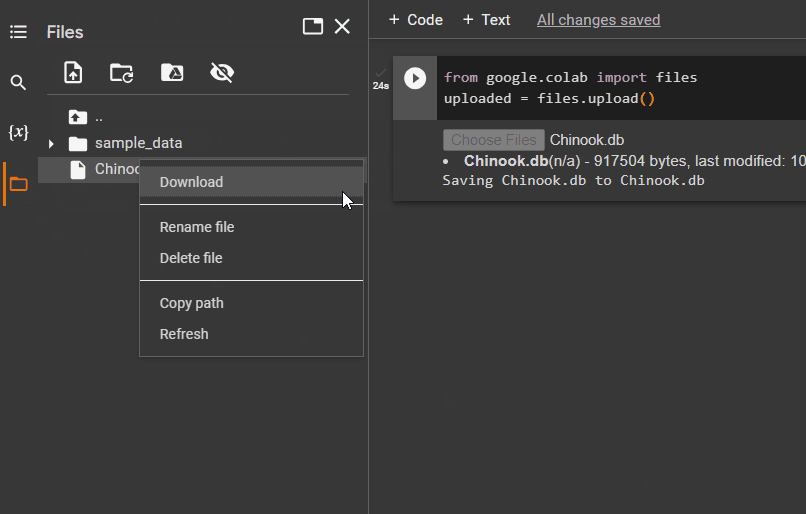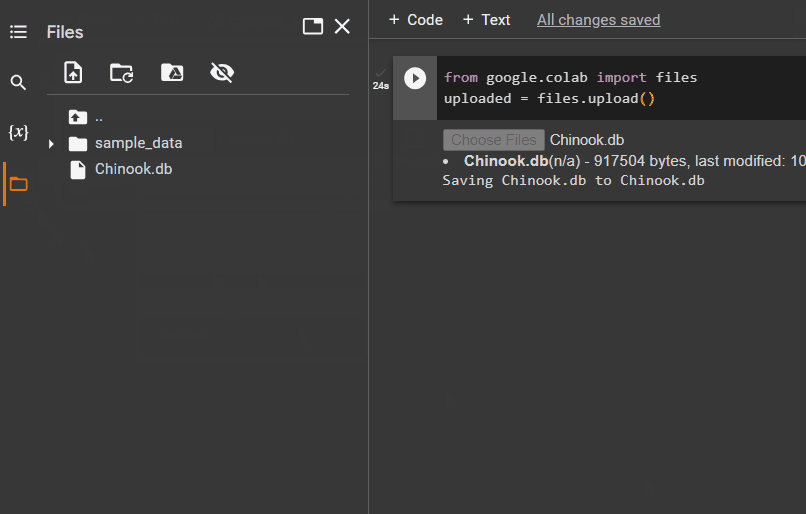
След като базата данни е изградена успешно, качете „.db“ файл към Google Collaboratory, като използвате следния код:
от google. ET AL импортиране файловекачен = файлове. качване ( )
Изберете файла от локалната система, като щракнете върху „Избор на файлове“ бутон след изпълнение на горния код:
След като файлът бъде качен, просто копирайте пътя на файла, който ще се използва в следващата стъпка:
Стъпка 6: Конфигуриране на езиков модел
Изградете езиковия модел, вериги, инструменти и вериги, като използвате следния код:
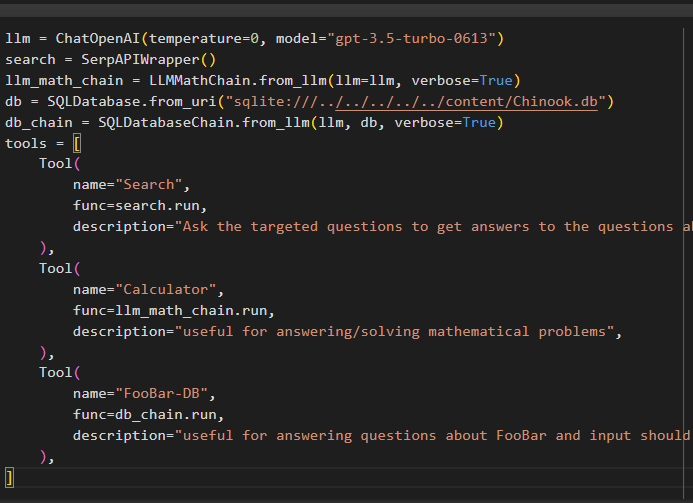
llm = ChatOpenAI ( температура = 0 , модел = 'gpt-3.5-turbo-0613' )Търсене = SerpAPIWrapper ( )
llm_math_chain = LLMMathChain. from_llm ( llm = llm , многословен = Вярно )
db = SQLDatabase. from_uri ( 'sqlite:///../../../../../content/Chinook.db' )
db_chain = SQLDatabaseChain. from_llm ( llm , db , многословен = Вярно )
инструменти = [
Инструмент (
име = 'Търсене' ,
функ = Търсене. бягам ,
описание = „Задайте целевите въпроси, за да получите отговори на въпросите за последните афери“ ,
) ,
Инструмент (
име = 'Калкулатор' ,
функ = llm_math_chain. бягам ,
описание = 'полезно за отговаряне/решаване на математически задачи' ,
) ,
Инструмент (
име = 'FooBar-DB' ,
функ = db_chain. тичам ,
описание = 'полезно за отговаряне на въпроси относно FooBar и въвеждането трябва да бъде под формата на въпрос, съдържащ пълен контекст' ,
) ,
]
- The llm променливата съдържа конфигурациите на езиковия модел, използвайки метода ChatOpenAI() с името на модела.
- Търсенето променливата съдържа метода SerpAPIWrapper() за изграждане на инструментите за агента.
- Изградете llm_math_chain за да получите отговорите, свързани с областта на математиката, като използвате метода LLMMathChain().
- Променливата db съдържа пътя на файла, който съдържа съдържанието на базата данни. Потребителят трябва да промени само последната част, която е „съдържание/Chinook.db“ на пътя поддържане на „sqlite:///../../../../../“ същото.
- Изградете друга верига за отговаряне на заявки от базата данни, като използвате db_chain променлива.
- Конфигурирайте инструменти като Търсене , калкулатор , и FooBar-DB за търсене на отговор, отговаряне на математически въпроси и съответно заявки от базата данни:
Стъпка 7: Добавяне на памет
След като конфигурирате функциите на OpenAI, просто изградете и добавете паметта към агента:
от Langchain. подкани импортиране MessagesPlaceholderот Langchain. памет импортиране ConversationBufferMemory
agent_kwargs = {
'extra_prompt_messages' : [ MessagesPlaceholder ( име_на_променлива = 'памет' ) ] ,
}
памет = ConversationBufferMemory ( памет_ключ = 'памет' , върнати_съобщения = Вярно )
Стъпка 8: Инициализиране на агента
Последният компонент за изграждане и инициализиране е агентът, съдържащ всички компоненти като llm , инструмент , OPENAI_FUNCTIONS и други, които да се използват в този процес:
агент = инициализиращ_агент (инструменти ,
llm ,
агент = AgentType. OPENAI_FUNCTIONS ,
многословен = Вярно ,
agent_kwargs = agent_kwargs ,
памет = памет ,
)
Стъпка 9: Тестване на агента
Накрая тествайте агента, като започнете чата с помощта на „ здрасти ” съобщение:
агент. тичам ( 'здравей' ) 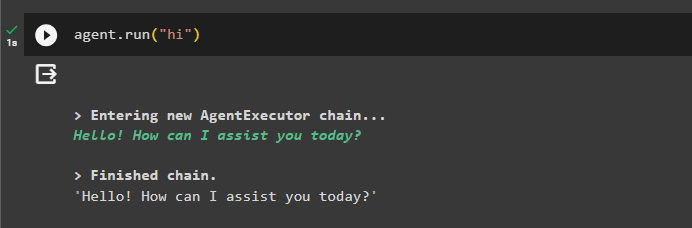
Добавете малко информация към паметта, като стартирате агента с нея:
агент. тичам ( 'Казвам се Джон сноу' ) 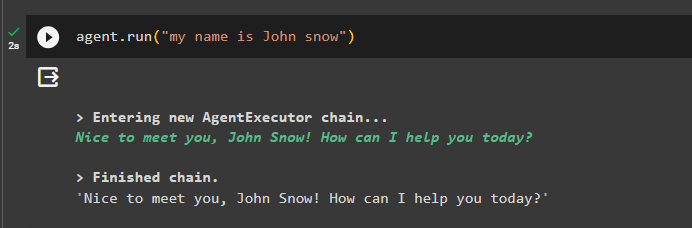
Сега тествайте паметта, като зададете въпроса за предишния чат:
агент. тичам ( 'Как е името ми' )Агентът е отговорил с името, извлечено от паметта, така че паметта работи успешно с агента:
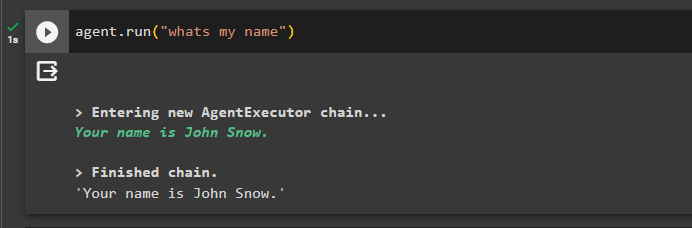
Това е всичко за сега.
Заключение
За да добавите памет към агента за функции на OpenAI в LangChain, инсталирайте модулите, за да получите зависимостите за импортиране на библиотеките. След това просто изградете базата данни и я качете в бележника на Python, за да може да се използва с модела. Конфигурирайте модела, инструментите, веригите и базата данни, преди да ги добавите към агента и да го инициализирате. Преди да тествате паметта, изградете паметта с помощта на ConversationalBufferMemory() и я добавете към агента, преди да я тествате. Това ръководство разработи подробно как да добавите памет към агента за функции на OpenAI в LangChain.