Как да използвам прозорец на буфер за разговори в LangChain?
Прозорецът на буфера за разговор се използва за запазване на най-новите съобщения от разговора в паметта, за да получите най-новия контекст. Той използва стойността на K за съхраняване на съобщения или низове в паметта, използвайки рамката LangChain.
За да научите процеса на използване на прозореца на буфера за разговор в LangChain, просто преминете през следното ръководство:
Стъпка 1: Инсталирайте модули
Стартирайте процеса на използване на прозореца на буфера за разговор, като инсталирате модула LangChain с необходимите зависимости за изграждане на модели на разговор:
pip инсталирайте langchain
След това инсталирайте модула OpenAI, който може да се използва за изграждане на големите езикови модели в LangChain:
pip инсталирайте openai
Сега, настройте среда OpenAI за изграждане на LLM вериги с помощта на API ключа от OpenAI акаунта:
импортиране Вие
импортиране getpass
Вие . приблизително [ „OPENAI_API_KEY“ ] = getpass . getpass ( „API ключ на OpenAI:“ )
Стъпка 2: Използване на паметта на прозореца на буфера за разговори
За да използвате паметта на прозореца на буфера за разговори в LangChain, импортирайте ConversationBufferWindowMemory библиотека:
от Langchain. памет импортиране ConversationBufferWindowMemoryКонфигурирайте паметта с помощта на ConversationBufferWindowMemory () метод със стойността на k като негов аргумент. Стойността на k ще се използва за запазване на най-новите съобщения от разговора и след това за конфигуриране на данните за обучение с помощта на входните и изходните променливи:
памет = ConversationBufferWindowMemory ( к = 1 )памет. save_context ( { 'вход' : 'Здравейте' } , { 'изход' : 'Как си' } )
памет. save_context ( { 'вход' : 'Аз съм добър, а ти' } , { 'изход' : 'не много' } )
Тествайте паметта, като се обадите на load_memory_variables () метод за започване на разговора:
памет. load_memory_variables ( { } ) 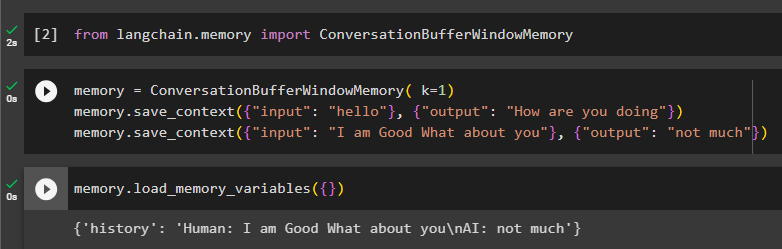
За да получите историята на разговора, конфигурирайте функцията ConversationBufferWindowMemory(), като използвате върнати_съобщения аргумент:
памет = ConversationBufferWindowMemory ( к = 1 , върнати_съобщения = Вярно )памет. save_context ( { 'вход' : 'здравей' } , { 'изход' : 'какво става' } )
памет. save_context ( { 'вход' : 'не много ти' } , { 'изход' : 'не много' } )
Сега извикайте паметта с помощта на load_memory_variables () метод за получаване на отговор с историята на разговора:
памет. load_memory_variables ( { } ) 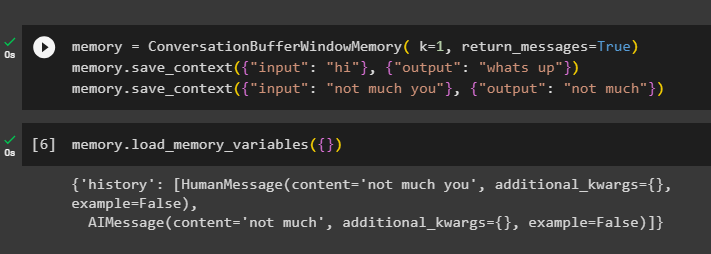
Стъпка 3: Използване на буферен прозорец във верига
Изградете веригата с помощта на OpenAI и ConversationChain библиотеки и след това конфигурирайте буферната памет да съхранява най-новите съобщения в разговора:
от Langchain. вериги импортиране ConversationChainот Langchain. llms импортиране OpenAI
#изграждане на резюме на разговора с помощта на множество параметри
разговор_с_резюме = ConversationChain (
llm = OpenAI ( температура = 0 ) ,
#изграждане на буфер на паметта, използвайки неговата функция със стойността на k за съхраняване на скорошни съобщения
памет = ConversationBufferWindowMemory ( к = 2 ) ,
#configure verbose променлива, за да получите по-четлив изход
многословен = Вярно
)
разговор_с_резюме. прогнозирам ( вход = 'Здрасти какво става' )
Сега продължете разговора, като зададете въпроса, свързан с изхода, предоставен от модела:
разговор_с_резюме. прогнозирам ( вход = 'Какви са техните проблеми' ) 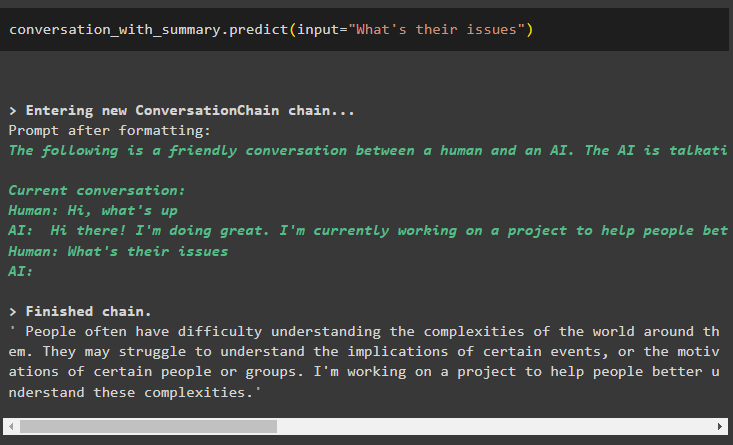
Моделът е конфигуриран да съхранява само едно предишно съобщение, което може да се използва като контекст:
разговор_с_резюме. прогнозирам ( вход = 'добре ли върви' ) 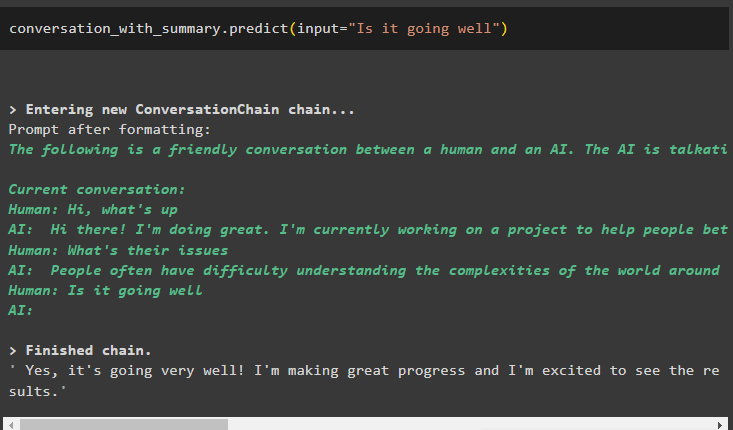
Поискайте решението на проблемите и изходната структура ще продължи да плъзга прозореца на буфера, като премахва по-ранните съобщения:
разговор_с_резюме. прогнозирам ( вход = 'Какво е решението' ) 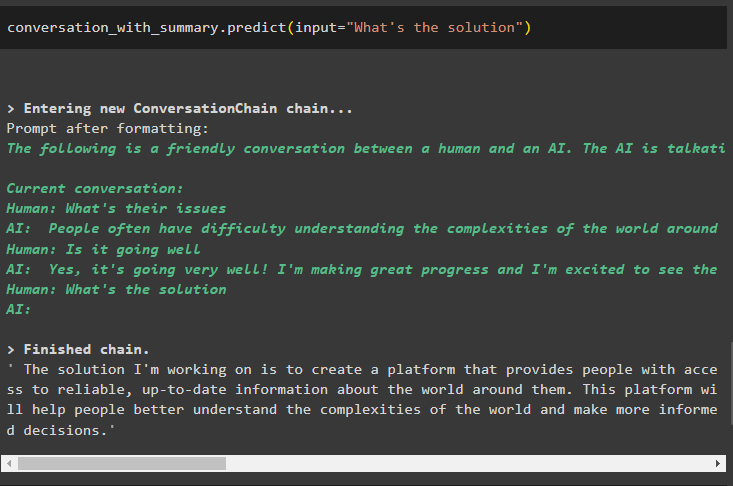
Това е всичко за процеса на използване на прозореца на буфера за разговори LangChain.
Заключение
За да използвате паметта на прозореца на буфера за разговори в LangChain, просто инсталирайте модулите и настройте средата с помощта на API ключа на OpenAI. След това изградете буферната памет, като използвате стойността на k, за да запазите най-новите съобщения в разговора, за да запазите контекста. Буферната памет може да се използва и с вериги за започване на разговор с LLM или верига. Това ръководство разработи подробно процеса на използване на прозореца на буфера за разговори в LangChain.