Това ръководство ще илюстрира как да използвате VectorStoreRetrieverMemory с помощта на рамката LangChain.
Как да използвам VectorStoreRetrieverMemory в LangChain?
VectorStoreRetrieverMemory е библиотеката на LangChain, която може да се използва за извличане на информация/данни от паметта с помощта на векторните хранилища. Векторните хранилища могат да се използват за съхраняване и управление на данни за ефективно извличане на информацията според подканата или заявката.
За да научите процеса на използване на VectorStoreRetrieverMemory в LangChain, просто преминете през следното ръководство:
Стъпка 1: Инсталирайте модули
Стартирайте процеса на използване на ретривъра на паметта, като инсталирате LangChain с помощта на командата pip:
pip инсталирайте langchain
Инсталирайте модулите FAISS, за да получите данните чрез търсенето на семантично сходство:
pip инсталирайте faiss-gpu 
Инсталирайте модула chromadb за използване на базата данни Chroma. Той работи като векторно хранилище за изграждане на паметта за ретривъра:
pip инсталирайте chromadb 
Необходим е друг модул tiktoken за инсталиране, който може да се използва за създаване на токени чрез преобразуване на данни в по-малки части:
pip инсталирайте tiktoken 
Инсталирайте модула OpenAI, за да използвате неговите библиотеки за изграждане на LLM или chatbots, използвайки неговата среда:
pip инсталирайте openai 
Настройте средата на Python IDE или бележник, като използвате API ключа от OpenAI акаунта:
импортиране Виеимпортиране getpass
Вие . приблизително [ „OPENAI_API_KEY“ ] = getpass . getpass ( „API ключ на OpenAI:“ )
Стъпка 2: Импортирайте библиотеки
Следващата стъпка е да получите библиотеките от тези модули за използване на инструмента за извличане на памет в LangChain:
от Langchain. подкани импортиране PromptTemplateот Време за среща импортиране Време за среща
от Langchain. llms импортиране OpenAI
от Langchain. вграждания . openai импортиране OpenAIEmbeddings
от Langchain. вериги импортиране ConversationChain
от Langchain. памет импортиране VectorStoreRetrieverMemory
Стъпка 3: Инициализиране на Vector Store
Това ръководство използва базата данни Chroma след импортиране на библиотеката FAISS, за да извлече данните с помощта на командата за въвеждане:
импортиране фаисот Langchain. docstore импортиране InMemoryDocstore
#importing библиотеки за конфигуриране на бази данни или векторни хранилища
от Langchain. векторни магазини импортиране ФАЙС
#създайте вграждания и текстове, за да ги съхранявате във векторните хранилища
размер_вграждане = 1536
индекс = фаис. IndexFlatL2 ( размер_вграждане )
вграждане_fn = OpenAIEmbeddings ( ) . embed_query
векторен магазин = ФАЙС ( вграждане_fn , индекс , InMemoryDocstore ( { } ) , { } )
Стъпка 4: Изграждане на Retriever, подкрепено от Vector Store
Изградете паметта, за да съхранявате най-новите съобщения в разговора и да получите контекста на чата:
ретривър = векторен магазин. as_retriever ( search_kwargs = дикт ( к = 1 ) )памет = VectorStoreRetrieverMemory ( ретривър = ретривър )
памет. save_context ( { 'вход' : 'Обичам да ям пица' } , { 'изход' : 'фантастичен' } )
памет. save_context ( { 'вход' : „Добър съм във футбола“ } , { 'изход' : 'Добре' } )
памет. save_context ( { 'вход' : 'Не харесвам политиката' } , { 'изход' : 'сигурен' } )
Тествайте паметта на модела, като използвате въведените от потребителя данни с неговата история:
печат ( памет. load_memory_variables ( { 'бързо' : 'какъв спорт да гледам?' } ) [ 'история' ] ) 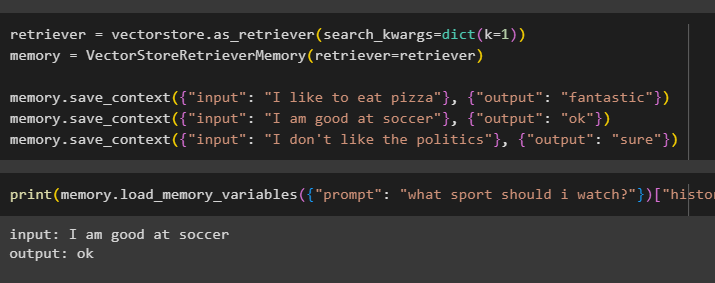
Стъпка 5: Използване на Retriever във верига
Следващата стъпка е използването на инструмент за извличане на памет с веригите чрез изграждане на LLM с помощта на метода OpenAI() и конфигуриране на шаблона за подкана:
llm = OpenAI ( температура = 0 )_DEFAULT_TEMPLATE = '''Това е взаимодействие между човек и машина
Системата произвежда полезна информация с подробности, използвайки контекста
Ако системата няма отговор за вас, тя просто казва, че нямам отговора
Важна информация от разговора:
{история}
(ако текстът не е подходящ, не го използвайте)
Текущ чат:
Човек: {вход}
AI:'''
ПОДКАЗВАНЕ = PromptTemplate (
входни_променливи = [ 'история' , 'вход' ] , шаблон = _DEFAULT_TEMPLATE
)
#конфигурирайте ConversationChain(), като използвате стойностите за неговите параметри
разговор_с_резюме = ConversationChain (
llm = llm ,
подкана = ПОДКАЗВАНЕ ,
памет = памет ,
многословен = Вярно
)
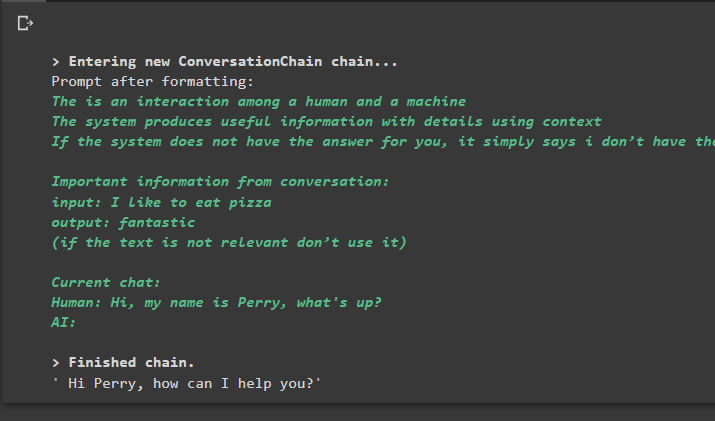
разговор_с_резюме. прогнозирам ( вход = „Здрасти, казвам се Пери, какво има?“ )
Изход
Изпълнението на командата стартира веригата и показва отговора, предоставен от модела или LLM:
Продължете с разговора, като използвате подканата въз основа на данните, съхранени във векторното хранилище:
разговор_с_резюме. прогнозирам ( вход = 'кой е любимият ми спорт?' ) 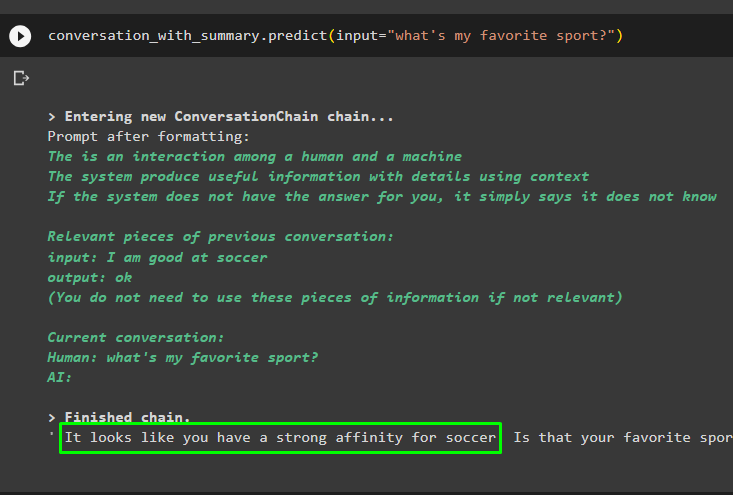
Предишните съобщения се съхраняват в паметта на модела, която може да се използва от модела, за да разбере контекста на съобщението:
разговор_с_резюме. прогнозирам ( вход = „Коя е любимата ми храна“ ) 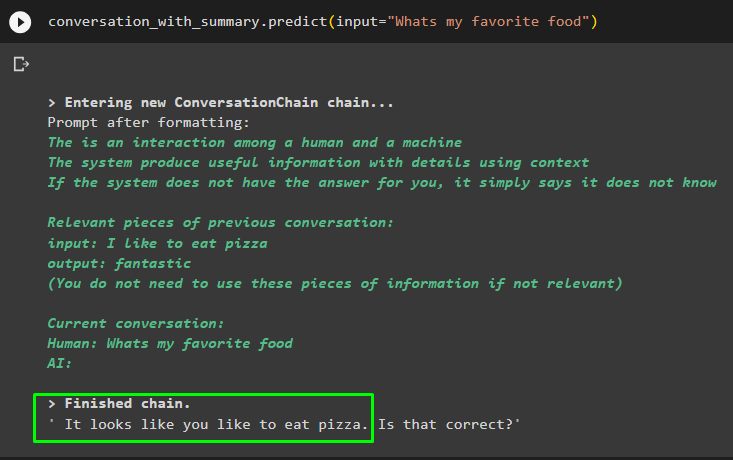
Получете отговора, предоставен на модела в едно от предишните съобщения, за да проверите как програмата за извличане на памет работи с чат модела:
разговор_с_резюме. прогнозирам ( вход = 'Как е името ми?' )Моделът е показал правилно изхода, използвайки търсенето на подобие от данните, съхранени в паметта:
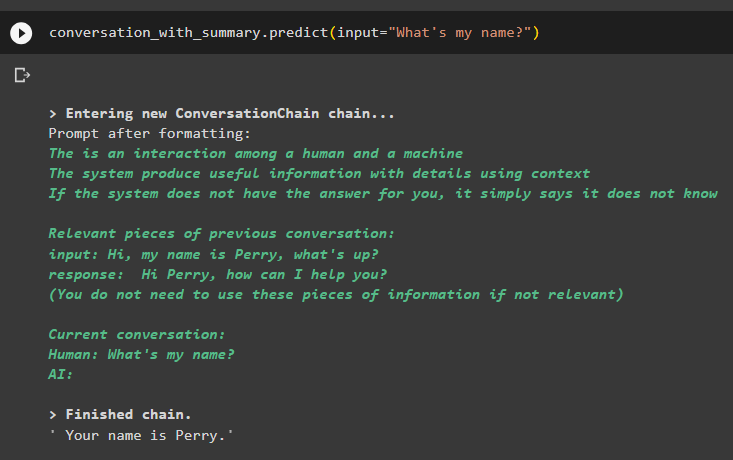
Това е всичко относно използването на инструмента за извличане на векторни магазини в LangChain.
Заключение
За да използвате инструмента за извличане на памет, базиран на векторно хранилище в LangChain, просто инсталирайте модулите и рамките и настройте средата. След това импортирайте библиотеките от модулите, за да изградите базата данни с помощта на Chroma и след това задайте шаблона за подкана. Тествайте ретривъра, след като съхраните данни в паметта, като започнете разговора и зададете въпроси, свързани с предишните съобщения. Това ръководство разработи подробно процеса на използване на библиотеката VectorStoreRetrieverMemory в LangChain.