Оптимизиране на кода на Python с инструменти за профилиране
Настройвайки Google Colab да работи за оптимизиране на кода на Python с инструменти за профилиране, започваме с настройка на среда на Google Colab. Ако сме нови в Colab, това е важна, мощна платформа, базирана на облак, която предоставя достъп до преносими компютри на Jupyter и набор от библиотеки на Python. Влизаме в Colab, като посетим (https://colab.research.google.com/) и създадем нов бележник на Python.
Импортирайте библиотеките за профилиране
Нашата оптимизация разчита на професионалното използване на библиотеки за профилиране. Две важни библиотеки в този контекст са cProfile и line_profiler.
импортиране cProfile
импортиране line_profiler
Библиотеката “cProfile” е вграден инструмент на Python за профилиране на код, докато “line_profiler” е външен пакет, който ни позволява да отидем още по-дълбоко, анализирайки кода ред по ред.
В тази стъпка създаваме примерен скрипт на Python за изчисляване на последователността на Фибоначи с помощта на рекурсивна функция. Нека анализираме този процес по-задълбочено. Редицата на Фибоначи е набор от числа, в които всяко следващо число е сбор от двете предходни. Обикновено започва с 0 и 1, така че последователността изглежда като 0, 1, 1, 2, 3, 5, 8, 13, 21 и т.н. Това е математическа последователност, която обикновено се използва като пример в програмирането поради рекурсивния си характер.
Ние дефинираме функция на Python, наречена „Фибоначи“ в рекурсивната функция на Фибоначи. Тази функция приема цяло число „n“ като свой аргумент, представляващо позицията в редицата на Фибоначи, която искаме да изчислим. Искаме да намерим петото число в редицата на Фибоначи, например, ако „n“ е равно на 5.
деф фибоначи ( н ) :
След това установяваме основен случай. Базов случай при рекурсия е сценарий, който прекратява извикванията и връща предварително определена стойност. В редицата на Фибоначи, когато „n“ е 0 или 1, вече знаем резултата. 0-то и 1-во число на Фибоначи са съответно 0 и 1.
ако н <= 1 :връщане н
Този оператор „if“ определя дали „n“ е по-малко или равно на 1. Ако е така, връщаме самото „n“, тъй като няма нужда от допълнителна рекурсия.
Рекурсивно изчисление
Ако „n“ надвишава 1, продължаваме с рекурсивното изчисление. В този случай трябва да намерим „n“-то число на Фибоначи, като сумираме „(n-1)“-то и „(n-2)“-то число на Фибоначи. Постигаме това, като правим две рекурсивни извиквания във функцията.
друго :връщане фибоначи ( н - 1 ) + фибоначи ( н - 2 )
Тук „fibonacci(n – 1)“ изчислява „(n-1)“-тото число на Фибоначи, а „fibonacci(n – 2)“ изчислява „(n-2)“-тото число на Фибоначи. Събираме тези две стойности, за да получим желаното число на Фибоначи на позиция „n“.
В обобщение, тази функция „фибоначи“ рекурсивно изчислява числата на Фибоначи, като разделя проблема на по-малки подпроблеми. Той прави рекурсивни извиквания, докато достигне базовите случаи (0 или 1), връщайки известни стойности. За всеки друг „n“ той изчислява числото на Фибоначи чрез сумиране на резултатите от две рекурсивни извиквания за „(n-1)“ и „(n-2)“.
Въпреки че тази реализация е лесна за изчисляване на числата на Фибоначи, тя не е най-ефективната. В по-късните стъпки ще използваме инструментите за профилиране, за да идентифицираме и оптимизираме неговите ограничения за производителност за по-добро време за изпълнение.
Профилиране на кода с CProfile
Сега профилираме нашата функция „фибоначи“, като използваме „cProfile“. Това упражнение за профилиране предоставя представа за времето, изразходвано от всяко извикване на функция.
cprofiler = cProfile. Профил ( )cprofiler. активирайте ( )
резултат = фибоначи ( 30 )
cprofiler. деактивирайте ( )
cprofiler. print_stats ( вид = 'кумулативен' )
В този сегмент инициализираме обект „cProfile“, активираме профилирането, изискваме функцията „фибоначи“ с „n=30“, деактивираме профилирането и показваме статистиката, която е сортирана по кумулативно време. Това първоначално профилиране ни дава общ преглед на високо ниво кои функции отнемат най-много време.
! pip инсталирайте line_profilerимпортиране cProfile
импортиране line_profiler
деф фибоначи ( н ) :
ако н <= 1 :
връщане н
друго :
връщане фибоначи ( н - 1 ) + фибоначи ( н - 2 )
cprofiler = cProfile. Профил ( )
cprofiler. активирайте ( )
резултат = фибоначи ( 30 )
cprofiler. деактивирайте ( )
cprofiler. print_stats ( вид = 'кумулативен' )
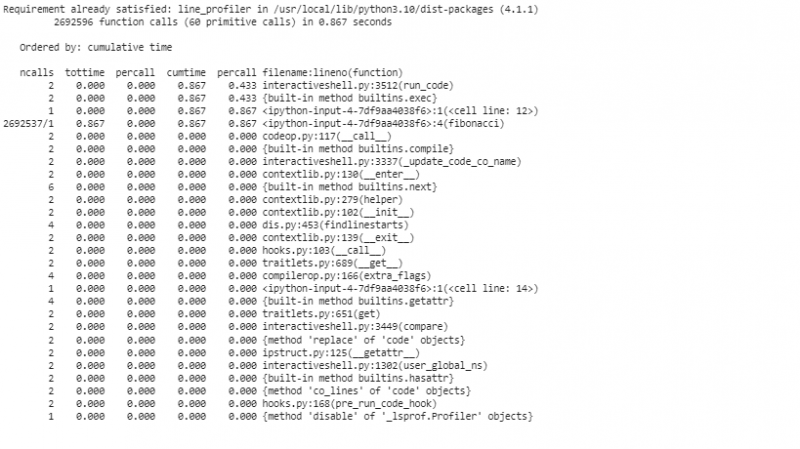
За да профилираме кода ред по ред с line_profiler за по-подробен анализ, ние използваме „line_profiler“, за да сегментираме нашия код ред по ред. Преди да използваме „line_profiler“, трябва да инсталираме пакета в хранилището на Colab.
! pip инсталирайте line_profilerСега, когато имаме готов „line_profiler“, можем да го приложим към нашата функция „fibonacci“:
% load_ext line_profilerдеф фибоначи ( н ) :
ако н <= 1 :
връщане н
друго :
връщане фибоначи ( н - 1 ) + фибоначи ( н - 2 )
%lprun -f фибоначи фибоначи ( 30 )
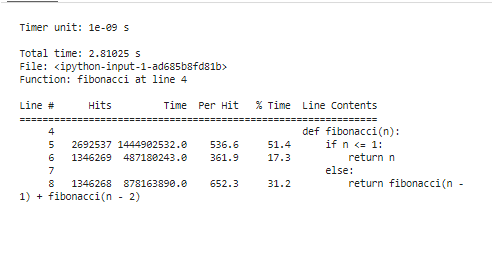
Този фрагмент започва със зареждане на разширението „line_profiler“, дефинира нашата функция „fibonacci“ и накрая използва „%lprun“, за да профилира функцията „fibonacci“ с „n=30“. Той предлага сегментиране ред по ред на времето за изпълнение, като прецизно изчиства къде нашият код изразходва своите ресурси.
След стартиране на инструментите за профилиране за анализ на резултатите, той ще бъде представен с масив от статистически данни, които показват характеристиките на ефективността на нашия код. Тези статистики включват общото време, изразходвано за всяка функция, и продължителността на всеки ред код. Например, можем да различим, че функцията на Фибоначи инвестира малко повече време за преизчисляване на еднаквите стойности многократно. Това е излишното изчисление и е ясна област, където може да се приложи оптимизация, или чрез мемоизация, или чрез използване на итеративни алгоритми.
Сега правим оптимизации там, където идентифицирахме потенциална оптимизация в нашата функция на Фибоначи. Забелязахме, че функцията преизчислява едни и същи числа на Фибоначи многократно, което води до ненужно излишък и по-бавно време за изпълнение.
За да оптимизираме това, прилагаме мемоизацията. Мемоизацията е техника за оптимизиране, която включва съхраняване на предварително изчислените резултати (в този случай числата на Фибоначи) и повторното им използване, когато е необходимо, вместо преизчисляването им. Това намалява излишните изчисления и подобрява производителността, особено за рекурсивни функции като последователността на Фибоначи.
За да внедрим мемоизацията в нашата функция на Фибоначи, ние пишем следния код:
# Речник за съхраняване на изчислени числа на Фибоначиfib_cache = { }
деф фибоначи ( н ) :
ако н <= 1 :
връщане н
# Проверете дали резултатът вече е кеширан
ако н в fib_cache:
връщане fib_cache [ н ]
друго :
# Изчислете и кеширайте резултата
fib_cache [ н ] = фибоначи ( н - 1 ) + фибоначи ( н - 2 )
връщане fib_cache [ н ] ,
В тази модифицирана версия на функцията „фибоначи“ въвеждаме речник „fib_cache“ за съхраняване на изчислените преди това числа на Фибоначи. Преди да изчислим число на Фибоначи, ние проверяваме дали вече е в кеша. Ако е така, връщаме кеширания резултат. Във всеки друг случай ние го изчисляваме, съхраняваме го в кеша и след това го връщаме.
Повтаряне на профилирането и оптимизацията
След внедряване на оптимизацията (запаметяване в нашия случай), от решаващо значение е да повторите процеса на профилиране, за да разберете въздействието на нашите промени и да се уверите, че сме подобрили производителността на кода.
Профилиране след оптимизация
Можем да използваме същите инструменти за профилиране, „cProfile“ и „line_profiler“, за профилиране на оптимизираната функция на Фибоначи. Сравнявайки новите резултати от профилирането с предишните, можем да измерим ефективността на нашата оптимизация.
Ето как можем да профилираме оптимизираната функция 'фибоначи', използвайки 'cProfile':
cprofiler = cProfile. Профил ( )cprofiler. активирайте ( )
резултат = фибоначи ( 30 )
cprofiler. деактивирайте ( )
cprofiler. print_stats ( вид = 'кумулативен' )
Използвайки „line_profiler“, ние го профилираме ред по ред:
%lprun -f фибоначи фибоначи ( 30 )Код:
# Речник за съхраняване на изчислени числа на Фибоначиfib_cache = { }
деф фибоначи ( н ) :
ако н <= 1 :
връщане н
# Проверете дали резултатът вече е кеширан
ако н в fib_cache:
връщане fib_cache [ н ]
друго :
# Изчислете и кеширайте резултата
fib_cache [ н ] = фибоначи ( н - 1 ) + фибоначи ( н - 2 )
връщане fib_cache [ н ]
cprofiler = cProfile. Профил ( )
cprofiler. активирайте ( )
резултат = фибоначи ( 30 )
cprofiler. деактивирайте ( )
cprofiler. print_stats ( вид = 'кумулативен' )
%lprun -f фибоначи фибоначи ( 30 )
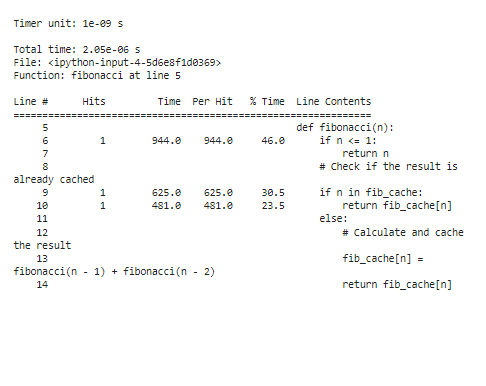
За да се анализират резултатите от профилирането след оптимизацията, ще има значително намалени времена за изпълнение, особено за големи „n“ стойности. Поради мемоизацията наблюдаваме, че функцията сега прекарва много по-малко време за преизчисляване на числата на Фибоначи.
Тези стъпки са от съществено значение в процеса на оптимизация. Оптимизирането включва извършване на информирани промени в нашия код въз основа на наблюденията, получени от профилирането, докато повтарящото се профилиране гарантира, че нашите оптимизации дават очакваните подобрения на производителността. Чрез итеративно профилиране, оптимизиране и валидиране можем да настроим фино нашия код на Python, за да осигурим по-добра производителност и да подобрим потребителското изживяване на нашите приложения.
Заключение
В тази статия обсъдихме примера, в който оптимизирахме кода на Python с помощта на инструменти за профилиране в средата на Google Colab. Инициализирахме примера с настройката, импортирахме основните библиотеки за профилиране, написахме примерните кодове, профилирахме го с помощта на „cProfile“ и „line_profiler“, изчислихме резултатите, приложихме оптимизациите и итеративно прецизирахме производителността на кода.