Данните се събират в огромни количества ежедневно и управлението на големи данни е най-важният случай на използване на Elasticsearch двигателя. Данните се съхраняват в базата данни за анализ в реално време и на потребителя е разрешено да извлича данни, за да намери полезни знания от тях, като използва заявки. Потребителят може да прилага заявки за намиране на данни от множество индекси и да ги показва в една кофа от релационната база данни.
Това ръководство ще обясни агрегатите Elasticsearch с примери, използващи различни агрегати.
Какво е агрегиране на Elasticsearch?
В Elasticsearch агрегирането е процесът на комбиниране или групиране на полетата за извличане на информация от релационната база данни. Агрегацията в Elasticsearch може да се разглежда като ГРУПИРАНЕ ПО КЛАУЗА или АГРЕГАТ() функция на езика SQL.
Как да използвам Elasticsearch Aggregation?
За да използва агрегацията в Elasticsearch, потребителят трябва да има основни познания за своята база данни. Нека проучим синтаксиса и неговото практическо приложение:
Синтаксис
За да намерите данни от базата данни, синтаксисът на агрегирането в машината Elasticsearch е както по-долу:
'aggs' : {'име_на_обединение' : {
'тип_на_агрегиране' : {
'поле' : 'име_на_поле_документ'
}
Горните фрагменти:
-
- Той използва „ aggs ”, която обяснява използването на агрегация в заявката.
- The име_на_обединение се задава от потребителя според необходимата информация.
- След това, тип_на_обединяване се използва за получаване на данни.
- Последният ред използва поле ключова дума, която е последвана от името на атрибута от документа.
Пример 1: Агрегиране в примерни данни на Kibana
Този раздел обяснява агрегирането с помощта на пример, използващ примерните данни от Kibana, като първо се свържете с него. След това просто отидете в „ Инструменти за разработка ”, като го потърсите от лентата за търсене и щракнете върху него:
Извличане на данни от примерни данни
Просто използвайте следната команда, за да извлечете данните от „ kibana_sample_data_logs ” на конзолата Dev Tools:
ВЗЕМЕТЕ / kibana_sample_data_logs / _Търсене
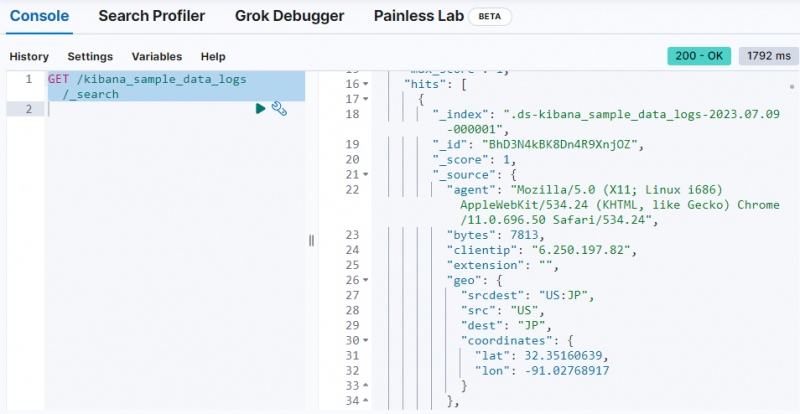
Резултатът показва, че данните са извлечени от „ kibana_sample_data_logs ” индекс.
Следният код използва a ВЗЕМЕТЕ заявка на „ kibana_sample_data_log ”, за да търсите от него с помощта на агрегацията value_count на „ clientip ” поле:
ВЗЕМЕТЕ / kibana_sample_data_logs / _Търсене{ 'размер' : 0 ,
'aggs' : {
'ip_count' : {
'стойност_брой' : {
'поле' : 'клиентска информация'
}
}
}
}
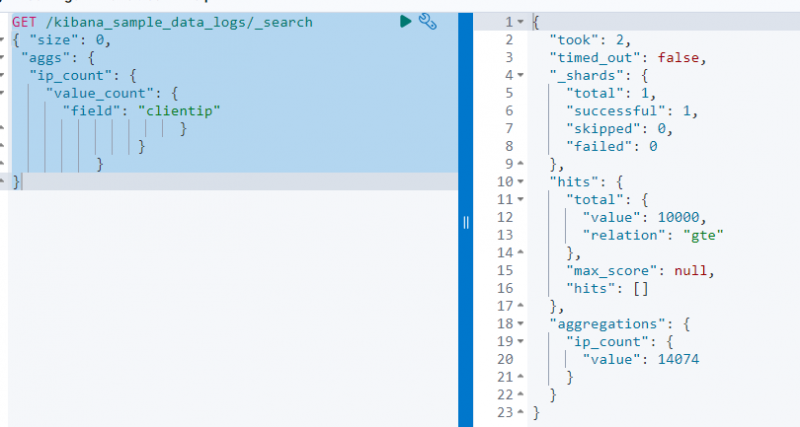
Екранната снимка по-горе показва агрегирането на clientip поле със стойността 14074 .
Важни агрегации
Някои от важните агрегати, които се използват за ефективно намиране на данни от базата данни, са споменати по-долу:
Следващите примери обясняват гореспоменатите агрегирания с помощта на ВЗЕМЕТЕ искане от „ kibana_sample_data_ecommerce ” индекс:
Кардинално агрегиране
Следният код използва „ кардиналност ” агрегиране на „ sku ” от данните за електронната търговия. Изпълнението на този код ще получи агрегиране с една стойност, за да получите уникалните SKU от базата данни Elasticsearch:
ВЗЕМЕТЕ / kibana_sample_data_ecommerce / _Търсене{
'размер' : 0 ,
'aggs' : {
'unique_skus' : {
'кардиналност' : {
'поле' : 'sku'
}
}
}
}
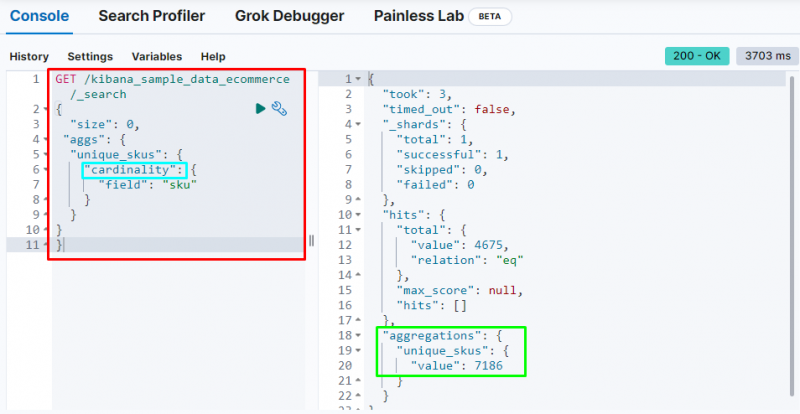
Той показва кардиналност агрегиране намиране на 7186 стойности от индекса.
Агрегиране на статистика
Друго важно агрегиране е „ статистика ' агрегиране, което се използва за получаване на ' броя ”, “ мин ”, “ макс ”, “ ср ', и ' сума ” статистика от „ общо количество ” поле:
ВЗЕМЕТЕ / kibana_sample_data_ecommerce / _Търсене{
'размер' : 0 ,
'aggs' : {
'quantity_stats' : {
'статистика' : {
'поле' : 'общо количество'
}
}
}
}
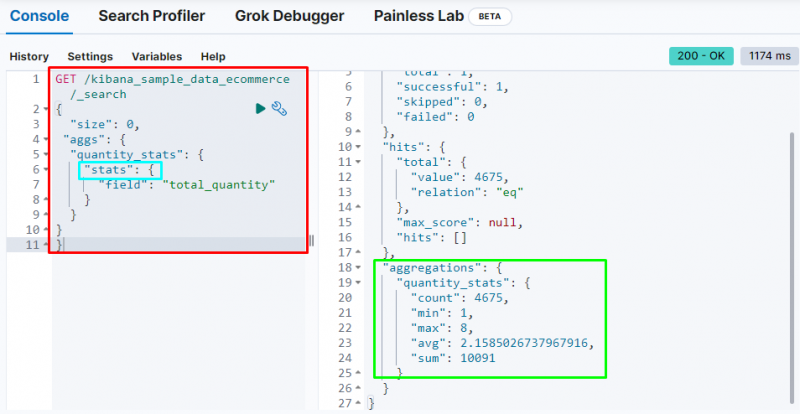
Екранната снимка по-горе показва статистиката в изхода от „ общо количество ” поле.
Филтърно агрегиране
Агрегирането на филтри се използва за филтриране на данни въз основа на термин или фраза от базата данни, тъй като го съдържа следният код:
ВЗЕМЕТЕ / kibana_sample_data_ecommerce / _Търсене{ 'размер' : 0 ,
'aggs' : {
'filter_aggregation' : {
'филтър' : {
'термин' : {
'потребител' : 'еди' } } ,
'aggs' : {
'цена_средна' : {
'ср.' : {
'поле' : 'продукти.цена' } }
} } } }
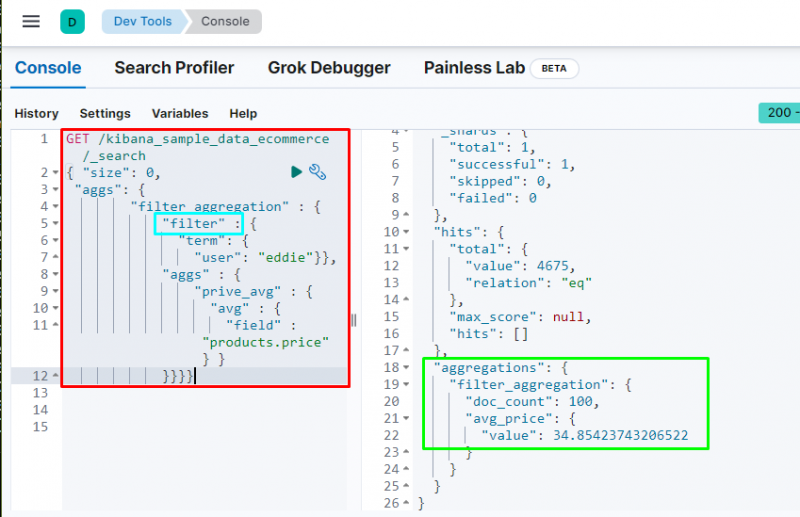
Изпълнението на код ще филтрира данните въз основа на „ еди ” и показва средната цена на закупените артикули. Горната екранна снимка показва, че потребител е намерил 100 пъти от данните и стойност от ср _ цена агрегиране.
Агрегиране на термини
Терминът агрегиране създава кофа и съхранява данни от полето в кофата и следният код използва „ потребител ”, за да съхранява данните си в кофата:
ВЗЕМЕТЕ / kibana_sample_data_ecommerce / _Търсене{
'размер' : 0 ,
'aggs' : {
„Агрегиране_на_термини“ : {
'условия' : {
'поле' : 'потребител'
}
}
}
}
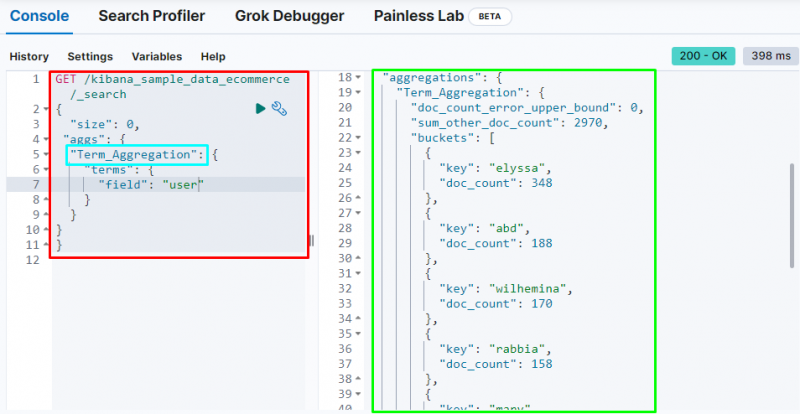
Следната екранна снимка показва, че агрегирането на термини е създало кофи за всеки потребител и техния брой документи.
Това е всичко за агрегирането на Elasticsearch и различното важно агрегиране.
Заключение
В Elasticsearch агрегацията се използва за получаване на данни от агрегираните документи и тези документи се извличат от конкретно поле. Обясняват се някои важни агрегати, които се използват за получаване на полезна информация от индексите. Това ръководство обяснява агрегирането на Elasticsearch и демонстрира процеса на използване на агрегирането на Elasticsearch.