Това ръководство ще обясни роботите за списъци в AWS.
Какво представляват списъците за обхождане в AWS?
Crawler е компонент на AWS Glue, който се използва за обхождане на местоположението на данните и извежда тази информация обратно в каталога. Информацията, която роботът събира, може да бъде типове данни на данните, структура на схема или с други думи, той събира метаданни. Crawler може да се използва и с каталога с данни, който се използва, когато данните се преместват в Glue екосистемата, докато се използват ETL задания и др.
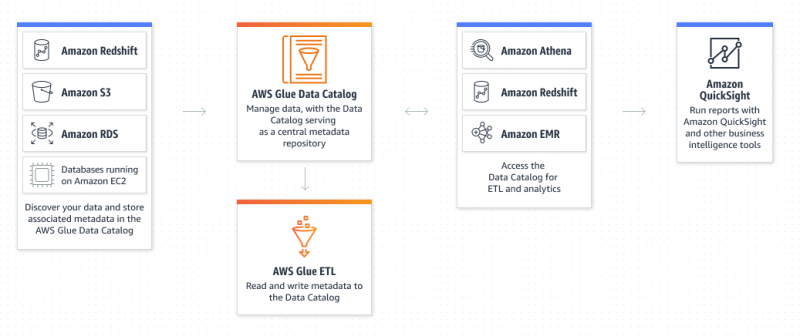
Какво представлява Amazon Glue Service?
AWS Glue е услуга на Amazon Extract Transform and Load, която позволява на потребителя да организира, локализира, премества и трансформира всички данни. AWS Glue е без сървър, тъй като потребителят не изисква да осигурява и конфигурира сървърите или да управлява жизнените цикли. Каталогът с данни и роботите са компонентите на AWS Glue, който действа като постоянно хранилище на метаданни:

Как да създадете робот на AWS?
За да създадете робот в AWS, посетете услугата AWS Glue от конзолата за управление на AWS:
Насочете се към „ Обхождащи машини ”, като щракнете върху името й от левия панел:
Кликнете върху „ Създаване на робот ” бутон:
Въведете името на робота и щракнете върху „ Следващия ” бутон:
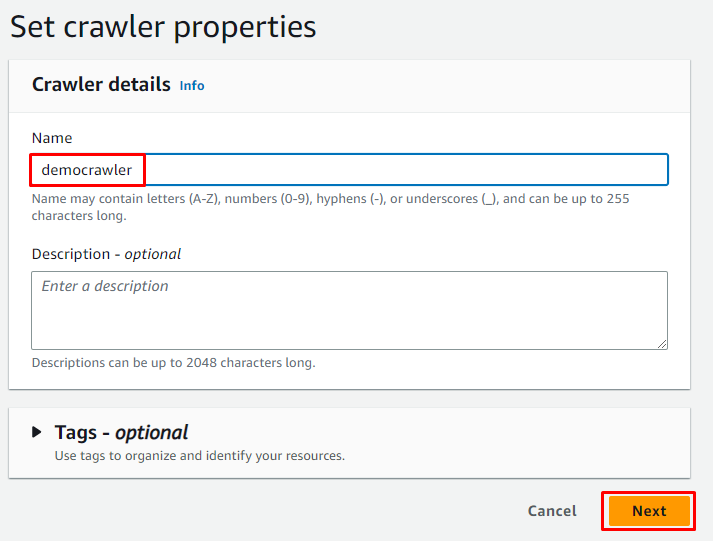
Изберете опцията за картографиране за залепващи таблици и щракнете върху „ Добавете източник ”, за да получите данни от:

Изберете услугата S3 и щракнете върху „ Прегледайте S3 ”, за да получите местоположението на източника:

Просто изберете папката S3 и щракнете върху „ Избирам ” бутон:

След като местоположението бъде добавено към източника, просто щракнете върху „ Добавете източник на данни S3 ” бутон:
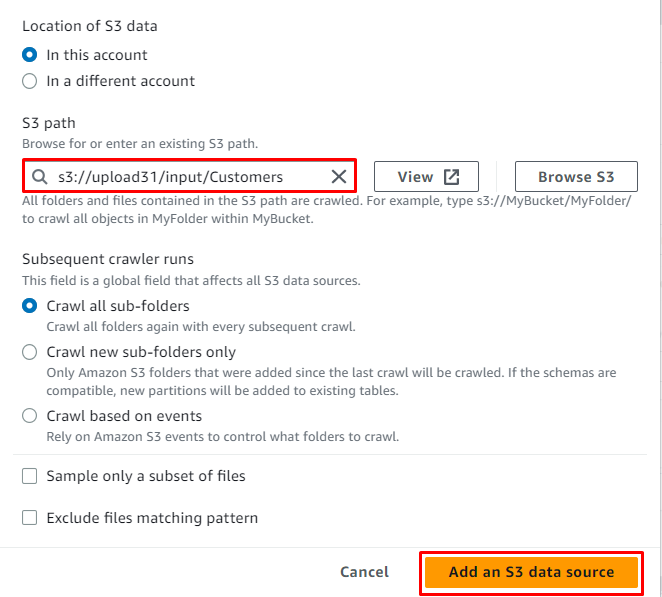
Кликнете върху „ Следващия ” бутон:

Кликнете върху „ Създайте нова IAM роля ” от бутона „ Конфигурирайте настройките за сигурност ” раздел:
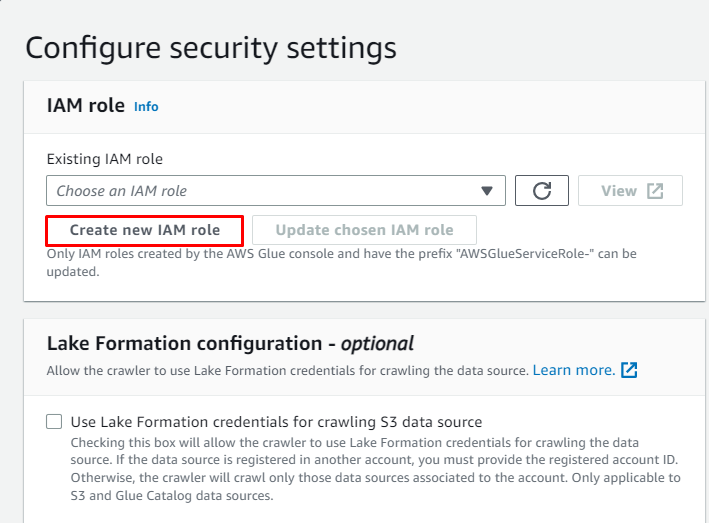
Въведете името на ролята и щракнете върху „ Създавайте ” бутон:
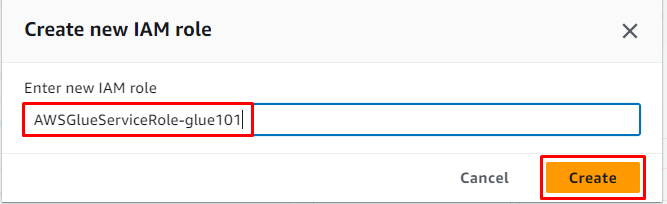
След това просто щракнете върху „ Следващия ” бутон:

Изберете целевата база данни и въведете името, което ще се използва за таблицата:
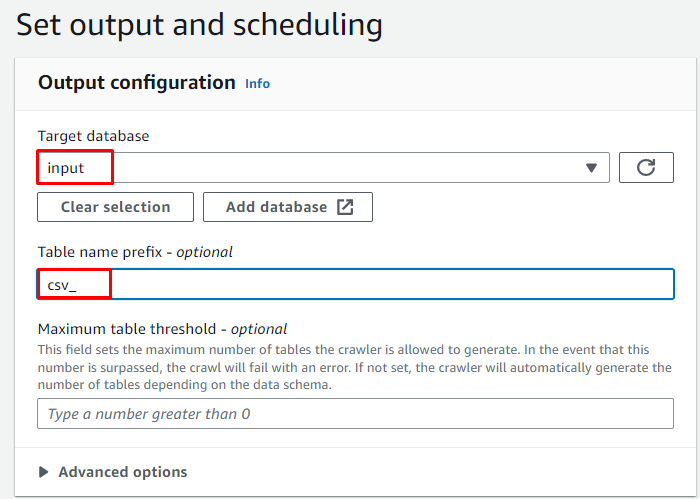
Планирайте робота за „ При поискване “ и щракнете върху „ Следващия ” бутон:
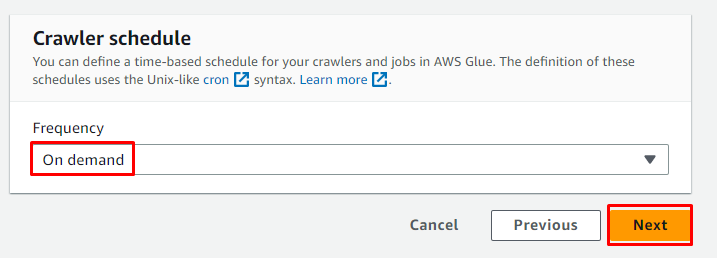
Прегледайте конфигурацията и щракнете върху „ Създаване на робот ” бутон:
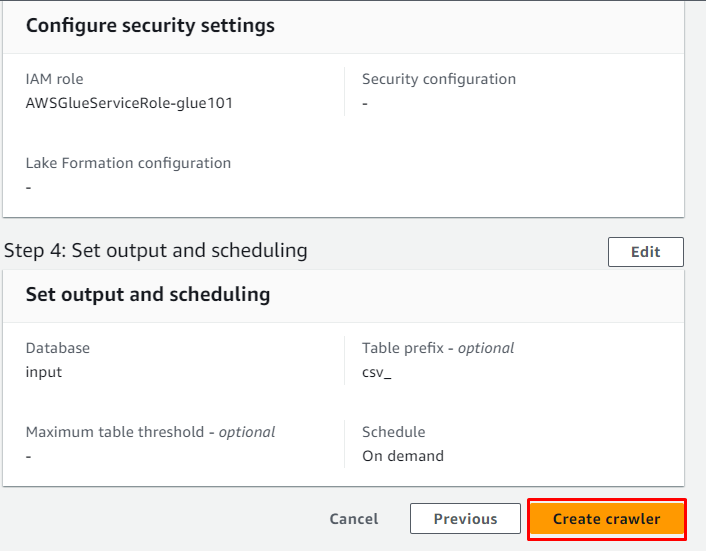
Роботът е създаден успешно и може да се използва за извличане на данните от източника, като щракнете върху „ Бягай ” бутон:

Това е всичко за обхождащите списъци в AWS.
Заключение
ListCrawler е компонентът на услугата AWS Glue, който може да се използва за обхождане на информация от източници и връщане към каталога. Каталозите с данни и роботите могат да се използват за събиране на данни за получаване на информация за данните, която е известна като метаданни. Потребителят може също да създаде робот от AWS Glue, за да получи данни от услугата S3 или други източници и да постави създадени таблици в базата данни. Това ръководство обяснява ListCrawlers в AWS и как да ги създадете.