„В „pandas“ можем лесно да прочетем текстовия файл с помощта на метода „pandas“. “Pandas” ни дава възможност да прочетем текстовия файл. “Pandas” дава различни вградени методи за четене на текстовия файл. Ще обсъдим всички методи в този урок заедно с всички параметри тук и ще ги обясним подробно. Освен това ще прочетем текстовия файл в „pandas“, като използваме методите на „pandas“ в нашите кодове тук.“
Методи за четене на текстов файл в „pandas“
В „pandas“ имаме три метода, които ни помагат при четенето на текстовия файл. Тук също направихме няколко примера, в които четем текстовия файл. Методите, които предоставя „пандите“, са разгледани по-долу:
-
- Чрез използване на метода pd.read_csv().
- Чрез използване на метода pd.read_table().
- Чрез използване на метода pd.read_fwf().
Сега обясняваме синтаксиса на всички тези методи и също така обсъждаме параметрите на всички методи подробно в този урок.
Синтаксис на read_csv()
pd.read_csv ( „име на файл.txt“, септ =' ', заглавка =Няма, имена = [ “Име_на_колона1”, “Име_на_колона2, “Име_на_колона2”, ………….. ] )
При този метод първо добавяме името на текстовия файл, чиито данни искаме да прочетем, и това е първият параметър на този метод. След това поставяме „sep“, който е разделител в този метод, и поставяме интервал тук като знак, така че да счита интервала за разделител. След това имаме параметъра на заглавката и се използва стойността „Няма“ на този параметър, така че ще създаде заглавката по подразбиране и ако не добавим този параметър, тогава ще вземе предвид първия ред на текстовия файл като заглавката. В параметъра „имена“ можем да добавим имената на колоните, които трябва да добавим като заглавка.
Синтаксис на read_table()
pd.read_table ( 'име на файл.txt' , разделител = ' ' )
В този метод ние поставяме името на текстовия файл като първи параметър. В разделителя, когато поставим „ “, той ще приеме знака за интервал като разделител.
Синтаксис на read_fwf()
pd.read_fwf ( 'име на файл.txt' )
Този метод приема само един параметър, който е името на текстовия файл.
Сега ще използваме тези методи за четене на текстовите файлове в кодове „pandas“ и показване на данните от текстовия файл на терминала.
Пример # 01
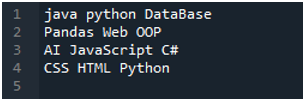
Приложението „Spyder“ е тук, в което сме направили всички тези кодове, които са представени в този урок. Текстовият файл, чиито данни искаме да прочетем, е показан по-долу. Ще използваме метода “read_csv()” за четене на този текстов файл в “pandas”.
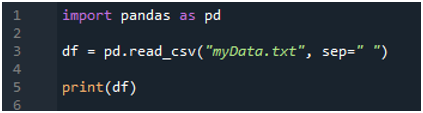
Първо импортираме библиотеката „pandas“, защото искаме да използваме метода „read_csv()“, а това е методът на „pandas“. Имаме достъп до този метод само когато сме импортирали библиотеката на „pandas“. Тук споменаваме „пандите като pd“, така че това „pd“ се поставя с името на метода за използването му. След това тук създаваме променлива “df”, която се използва за съхраняване на данните от текстовия файл след прочитане. Тук поставяме метода “pd.read_csv()”, който помага при четенето на текстовия файл и преобразуването на данните от текстовия файл в DataFrame и съхраняването им в променливата “df”.
Предадохме името на файла, което е „myData.txt“, тук и след това използваме „sep“ и присвояваме празния знак на този „sep“. И така, този празен знак работи като разделител в текстовия файл. След това използвахме „print()“ по-долу, който се използва за отпечатване на данните от текстовия файл. Той ще покаже данните от текстовия файл във формата DataFrame.
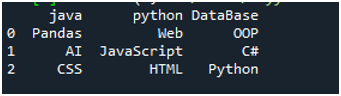
За да изпълним този код, трябва да натиснете „Shift+Enter“ и изходът ще бъде изобразен на терминала „Spyder“. Резултатът от горния код се показва на дадената екранна снимка и можете да видите, че данните от текстовия файл се показват като DataFrame, а първият ред на нашия текстов файл е представен тук като имената на колоните на тази DataFrame. Той също така разделя данните, където символът за интервал присъства в текстовия файл.
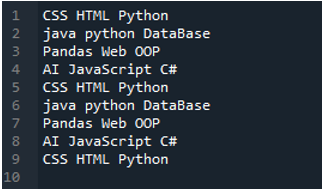
Пример # 02
Текстовият файл, който ще прочетем в този пример, е показан тук и ние отново ще използваме метода “read_csv()”, но с различни параметри.
Използва се методът „pandas“ „pd.read_csv()“ и тук предаваме три параметъра. Първо поставяме името на файла, което е „Record.txt“. Вторият параметър е параметърът „sep“ и му присвоява празния знак, а след това имаме третия параметър, в който задаваме „заглавието“ и го настройваме на „Няма“, така че ще създаде заглавката по подразбиране на DataFrame когато изпълним този код. Запазихме всичко това в променливата „My_Record“ и също добавихме „My_Record“ във функцията „print()“ за печат.

Всички данни се записват в DataFrame и той разделя данните, където символът за интервал присъства в данните на текстовия файл. Освен това създаде заглавката по подразбиране на DataFrame тук, защото коригирахме параметъра „header“ на „Няма“.
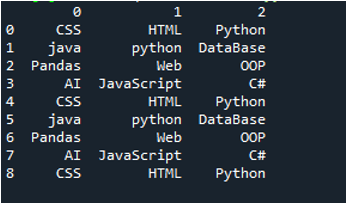
Пример # 03
Показва се текстовият файл на този пример и ние отново ще използваме метода „read_csv()“ с модифицирани параметри.
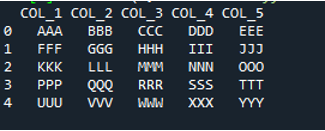
В този код тук се предават четири параметъра на метода „pandas“ „pd.read_csv()“. Името на текстовия файл е първият параметър. На параметъра “sep” се дава празен знак във втория параметър. Параметърът „header“ е зададен на „None“ в третия аргумент, а като четвърти параметър сме задали „names“, които ще се показват като имена на колони на DataFrame след прочитане на текстовия файл, и тези имена на колони са „COL_1, COL_2, COL_3, COL_4 и COL_5“. Цялата тази информация е запазена в променливата „My_Record“, а „My_Record“ също е добавена към метода „print()“, така че да се отпечатва на терминала.

Цялата информация на текстовия файл се изобразява тук като DataFrame и също така разделя данните, където се добавят интервалите в текстовия файл. Той също така добавя съответно имената на колоните, които сме добавили по-горе в кода.
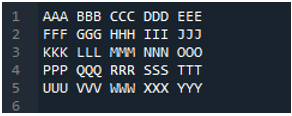
Пример # 04
Това е текстовият файл, който ще прочетем в този пример, като използваме друг метод, метода “pd.read_table()”.
Тук се добавя методът „pd.read_table()“ за четене на текстовия файл и добавяме „ABC.txt“, което е името на текстовия файл. Този метод помага при четенето на текстовия файл и също така сме коригирали параметъра „делимитер“ към знака за интервал, така че той също ще работи като разделителя, който обяснихме по-горе. След това всички данни на текстовия файл се записват в променливата „My_Data“ и също се отпечатват тук.

Първоначалният ред на нашия текстов файл е показан тук като имената на колоните на DataFrame, а данните от текстовия файл се отпечатват като DataFrame. Освен това той разделя данните от текстовия файл, където в него присъства знакът за интервал.
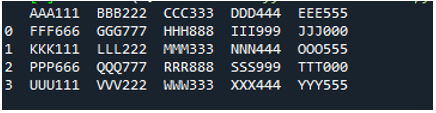
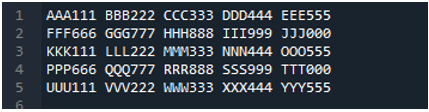
Пример # 05
Сега текстовият файл съдържа данните, които се показват по-долу. Този път ще приложим „read_fwf()“ и ще покажем как изобразява данни след прочитане на текстовия файл.
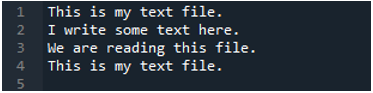
Както знаем, че този метод “read_fwf()” приема само един параметър, който е името на файла, който искаме да прочетем. Тук добавяме „textfile.txt“, което е името на нашия текстов файл и присвояваме този метод на pandas на променливата „File_Data“, която ще съхранява данните от този текстов файл. След това поставяме „print(File_Data)“, така че да отпечата и тези данни.

Тук се показват всички данни от текстовия файл. Не разделя данните, където има интервали, защото в тази функция няма параметър като „Sep“ или „delimiter“.
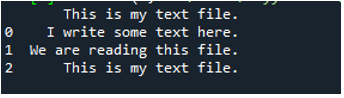
Заключение
Този урок обяснява как да четете текстовия файл в „pandas“ и кои методи се използват за четене на текстовия файл в „pandas“. Обсъдихме всички методи, които ни помагат да четем текстовия файл в „pandas“. В този урок проучихме три различни метода на „pandas“ за четене на нашите текстови файлове в „pandas“. Ние също така обяснихме синтаксиса на всички методи, както и параметрите на всички методи в подробности тук и прочетохме много текстови файлове чрез прилагане на различни методи с всички възможни параметри в този урок.