„Стойностите, разделени със запетая (CSV) са един от най-гъвкавите и лесни за използване формати на данни. Това е лек формат на данни, който позволява на разработчиците и приложенията да прехвърлят и анализират данни от един източник в друг.
CSV данните съхраняват данни в табличен формат, където всяка колона е разделена със запетая и нов запис се разпределя на нов ред. Това го прави много добър избор за експортиране на бази данни като SQL бази данни, данни на Cassandra и др.
Следователно не е изненадващо, че ще срещнете сценарий, при който трябва да импортирате CSV файл във вашата база данни.
Целта на този урок е да ви покаже бърз и лесен метод за импортиране на CSV файл във вашия клъстер Elasticsearch с помощта на таблото за управление на Kibana.“
Нека скочим.
Изисквания
Преди да се гмурнете, уверете се, че отговаряте на следните изисквания:
- Клъстер Elasticsearch със зелен здравен статус.
- Kibana сървър, свързан към вашия Elasticsearch клъстер.
- Достатъчни разрешения за управление на индекси на вашия клъстер.
Примерен CSV файл
Както обикновено, първото изискване е вашият изходен CSV файл. Добре е да се уверите, че данните във вашия CSV файл са добре форматирани и че не съдържат грешки.
За илюстративни цели ще използваме безплатен набор от данни, който съдържа филми и телевизионни предавания от Amazon Prime.
Отворете браузъра си и отворете ресурса по-долу:
https://www.kaggle.com/datasets/shivamb/amazon-prime-movies-and-tv-shows
Следвайте процедурата, за да изтеглите набора от данни на вашата локална машина. Можете да разархивирате изтегления архив с командата:
$ разархивирайте a~ / Изтегляния / archive.zip
Импортиране на CSV файл
След като подготвите своя изходен файл, можем да продължим и да обсъдим как да го импортираме.
Започнете, като се насочите към домашното табло за управление на Kibana и изберете опцията „качване на файл“.
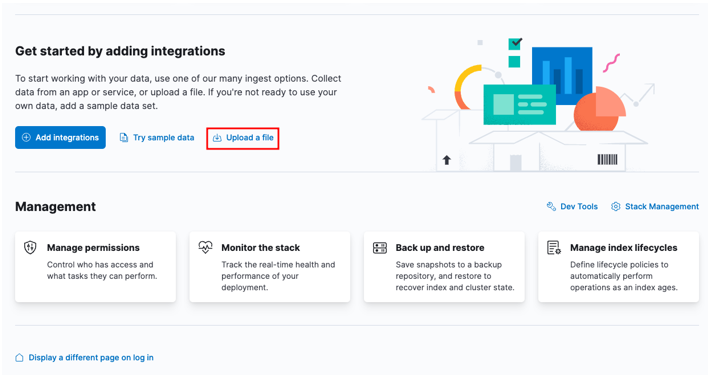
Намерете целевия CSV файл, който искате да импортирате, в прозореца на стартовия панел.
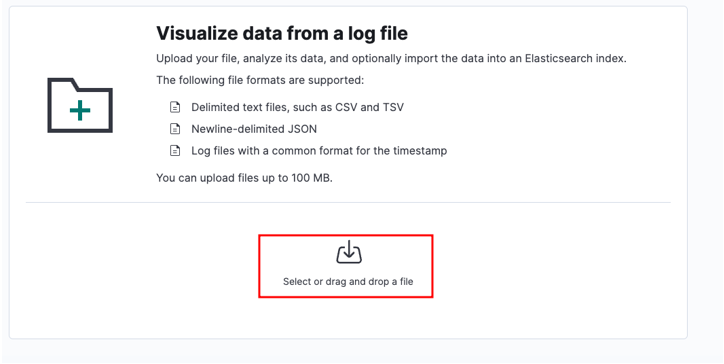
Изберете вашия изходен файл и щракнете върху качване.
Позволете на Elasticsearch и Kibana да анализират качения файл. Това ще анализира CSV файла и ще определи формата на данните, полетата, типовете данни и т.н.
ЗАБЕЛЕЖКА: В зависимост от конфигурацията на вашия клъстер и размера на данните, този процес може да отнеме известно време. Уверете се, че главният възел отговаря, за да избегнете изчакване.
След като процесът приключи, трябва да получите извадка от съдържанието на вашия файл и файловата статистика, анализирана от Elastic.
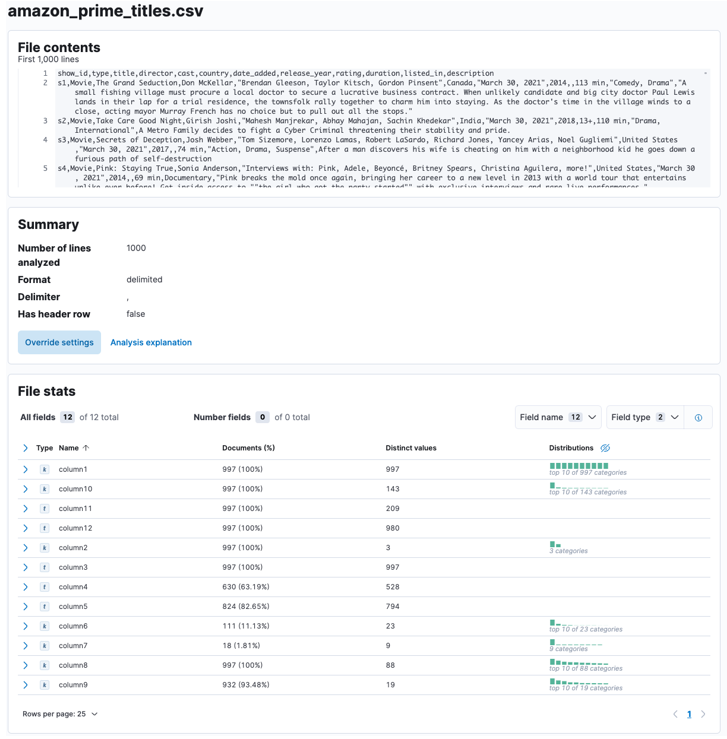
Можете да персонализирате множество параметри, например разделител, заглавни редове и т.н. Например, можем да персонализираме изхода по-горе, за да кажем на Elastic, че нашият CSV файл съдържа заглавни файлове.
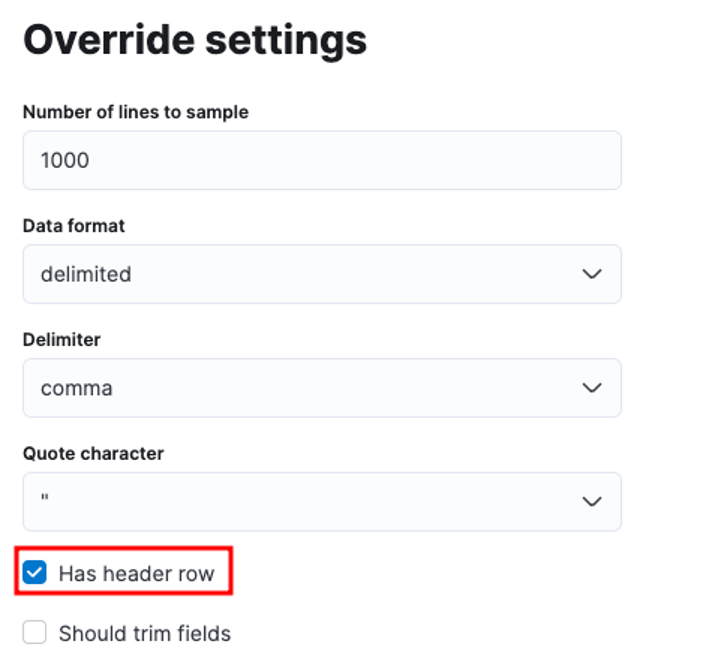
След това можем да щракнете върху Прилагане и да анализираме отново данните. Това трябва да форматира данните в правилния формат, включително полетата.
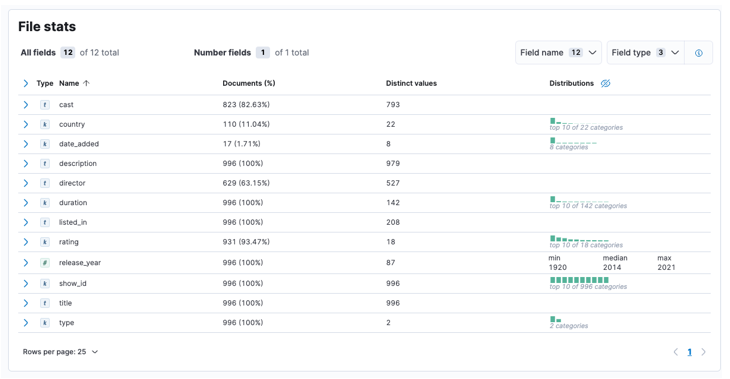
След това можем да щракнете върху импортиране, за да продължим към импортираното табло за управление.
Тук трябва да създадем индекс, в който да се съхраняват CSV данните. Можете да зададете всяко поддържано име към вашия индекс.
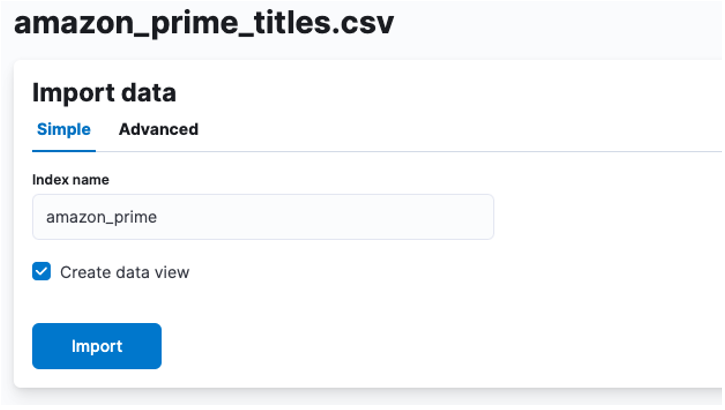
Ако желаете да персонализирате свойствата на вашия индекс, като например броя на сегментите, репликите, съпоставянията и т.н. Изберете разширената опция и настройте настройките си според вашите желания.
Накрая щракнете върху импортиране и гледайте как Kibana прави своята „магия“. След като приключите, можете да получите достъп до своя индекс или чрез API на Elasticsearch, или да използвате таблото за управление на Kibana.
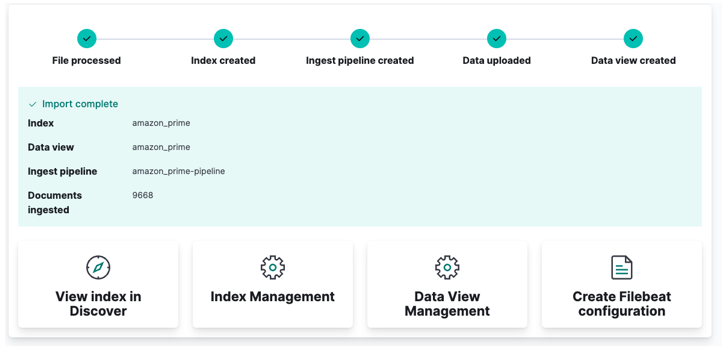
И сте готови!!
Заключение
В тази публикация разгледахме процеса на извличане и импортиране на вашия набор от CSV данни във вашия клъстер Elasticsearch с помощта на таблото за управление на Kibana.
Благодаря за четенето и приятно кодиране!!