Нека сега да разгледаме помощната програма iconv на Linux в неговата терминална конзола. И така, ние изпълняваме инструкцията „iconv“ с флага „-l“, за да покажем всички известни и най-използвани кодирани набори от знаци на нашия терминален екран. Той ще покаже кодираните набори от символи заедно с техните псевдоними. Можете да видите дълъг списък от кодирани набори от знаци, след като превъртите малко надолу.
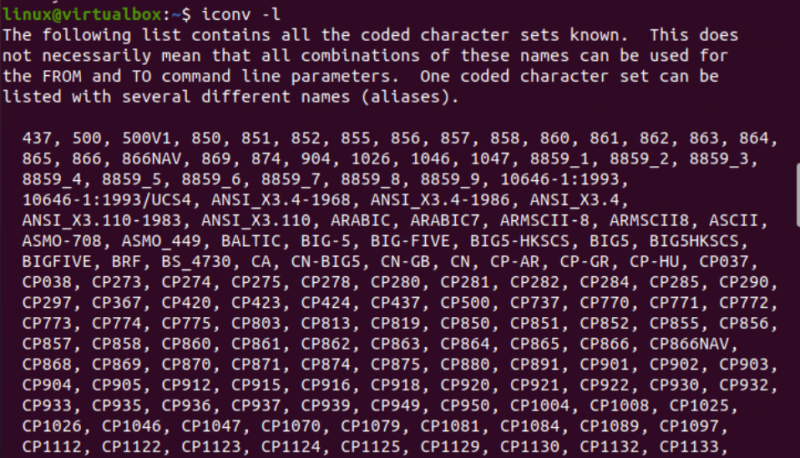
Сега е време да започнете с внедряването на командата iconv в Linux. Първо, имаме нужда от различни типове файлове в нашата система, за да конвертираме един тип файл в друг тип. По този начин ние използваме заявката „докосване“ в терминала на конзолата, за да създадем три различни файла, т.е. тип Java, тип C и тип текст. Изброявайки текущото съдържание на директорията, ще намерите новогенерираните файлове в нея.
След това ще разгледаме типа на всеки файл поотделно, като използваме заявката „файл“ заедно с името на всеки файл. Тази заявка се нуждае от опцията „-I“, за да покаже типа набор от кодиращи знаци за всеки файл поотделно. Ако сте забравили да използвате опцията „-I“, вместо това използвайте флага „—mime“. И двата флага „-I“ и „—mime“ работят еднакво.
Сега, след като изпълнихме инструкцията „файл“ за файла тип „txt“, получихме кодиране на типа символи „US-ASCII“. Докато се използва една и съща инструкция за Java и C файловете, това показва, че и двата файла съдържат „BINARY“ символен тип кодиране. Заедно с това тази инструкция показва, че и трите файла са празни.
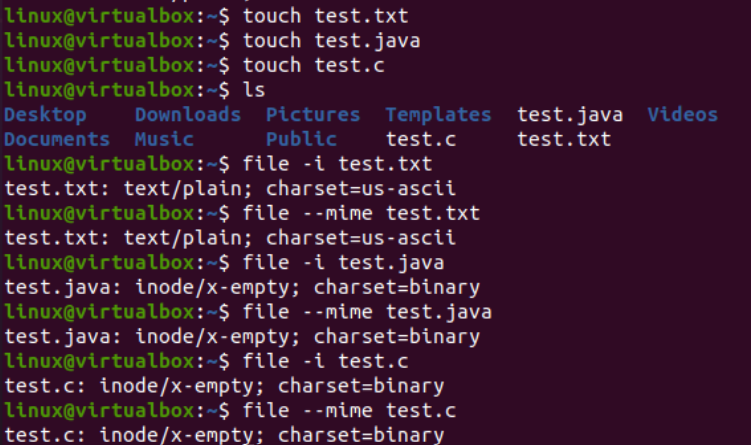
Сега ще илюстрираме използването на инструкцията iconv в конзолата за преобразуване на специфичен кодиращ файл за набор от символи в друг кодиращ набор от символи. Преди това трябва да добавим някакъв код или данни към нашите файлове. Затова добавихме Java кода във файла „text.java“, C кода във файла „text.c“ и добавихме текстови данни във файла „test.txt“. Заявката cat беше използвана тук за показване на съдържанието и на трите файла, както е представено по-долу:
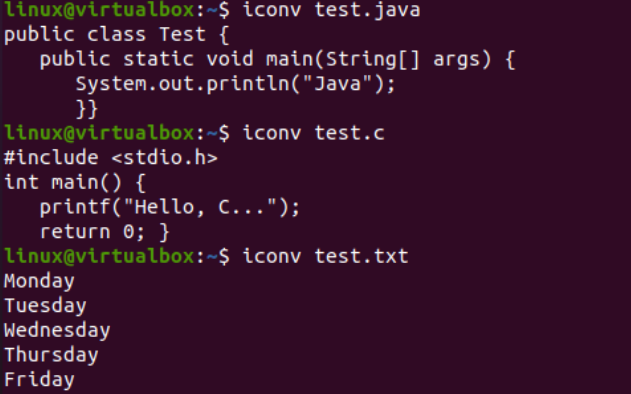
Сега, след като добавихме данните успешно, ще видим отново кодирането на набора от символи на тези файлове. И така, опитахме същата файлова инструкция в обвивката с флага „-I“ и имената на файловете, т.е. test.txt, test.java и test.c. Изпълнението на тези три инструкции поотделно за трите файла показва, че кодирането на набора от знаци е актуализирано за Java и C файловете, като остава същото за текстовия файл, т.е. US-ASCII. Кодирането на Java и C файлове преди това беше „двоично“; сега е „US-ASCII“. Освен това показва, че текстовият файл съдържа обикновени текстови данни, докато другите два кодови файла съдържат скриптовете като съдържание.

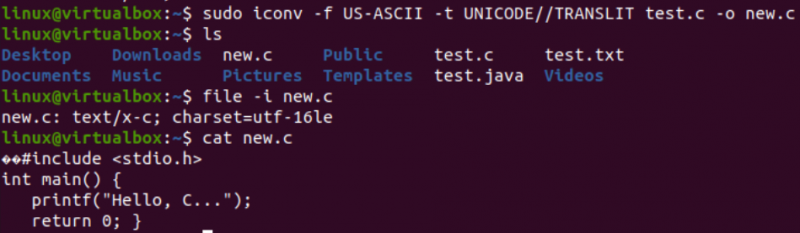
Време е да изпълним действителната задача, необходима за тази статия, т.е. да преобразуваме едно кодиране в друго с помощта на командата iconv в обвивката. По този начин ние използвахме инструкцията „iconv“ в терминала на обвивката с привилегиите „sudo“. Тази команда приема опцията „-f“ означава „от“, а опцията „-t“ означава „до“, т.е. от едно кодиране към друго.
След опцията „-f“ трябва да посочите кодирането, което вашият файл вече има, т.е. US-ASCII. Докато след опцията „-t“ трябва да посочите кодирането, което искате да замените със старото кодиране, т.е. UNICODE. Трябва да посочите името на файл, използван като източник с опцията –o, за да създадете изображение на неговия обект. Изображението на обекта ще бъде друг файл, т.е. „new.c“, от същия тип, но с новото кодиране и същите данни.
След като изпълните следната инструкция, ще получите нов файл в същата директория, т.е. според заявката „ls“. Сега ще проверим за кодирането на набора от символи на нов файл, генериран с помощта на инструкцията iconv. Отново ще използваме инструкцията „file“ с опцията „-I“ и новото име на файла, т.е. new.c.
Ще видите, че наборът от знаци за този нов файл е различен от набора от знаци на стар файл, т.е. наборът от знаци UTF-16LE. Това е така, защото сме превели кодирането US-ASCII в кодирането UNICODE, използвайки инструкцията iconv за нашия файл new.c. Заявката „cat“ показва същия C код във файла, но започва с някои Unicode знаци, както вече беше представено.
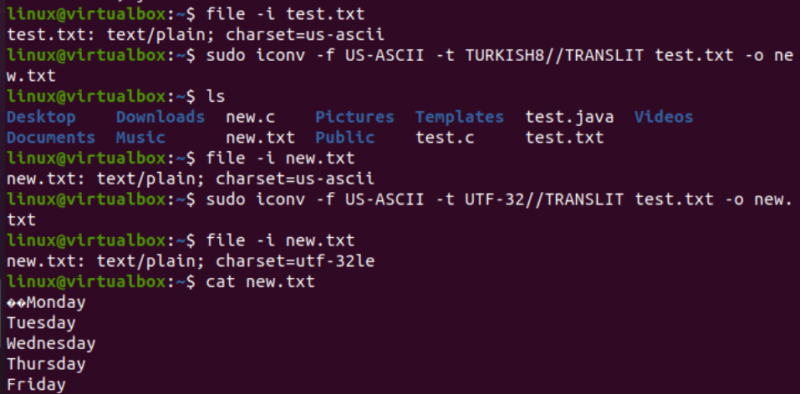
По много подобен начин ще променим кодирането на текстовия файл test.txt. Инструкцията на файла показва, че има кодиране на набор от символи US-ASCII. Командата iconv е използвана със същия формат за преобразуване на кодирането на файла test.txt от US-ASCII в TURKISH8. Ще видите, че това не променя US-ASCII на турски.
След това използвахме същата команда, за да покрием US-ASCII до UTF-32 кодиране на набор от знаци за същия файл. Този път работи. Това е така, защото понякога може да има проблем при преобразуването на един набор за кодиране в друг или другото кодиране може да не го поддържа.
Заключение
Тази статия обсъди как да използвате инструкциите на iconv Linux за преобразуване на един набор от кодиращи знаци в друг, като използвате техните псевдоними. По този начин трябваше да създадем няколко файла от различни типове.