Пандите попълват NaN стойности
Ако колона във вашата рамка с данни има стойности NaN или None, можете да използвате функциите „fillna()“ или „replace()“, за да ги попълните с нула (0).
запълване ()
Стойностите NA/NaN се попълват с предоставения подход с помощта на функцията „fillna()“. Може да се използва, като се вземе предвид следният синтаксис:
Ако искате да попълните NaN стойностите за една колона, синтаксисът е както следва:

Когато се изисква да попълните NaN стойностите за цялата DataFrame, синтаксисът е както е предоставен:

Замени()
За да замените една колона от NaN стойности, предоставеният синтаксис е както следва:

Докато, за да заменим NaN стойностите на цялата DataFrame, трябва да използваме следния споменат синтаксис:

В този текст сега ще проучим и научим практическото прилагане на двата метода за попълване на NaN стойностите в нашия Pandas DataFrame.
Пример 1: Попълване на NaN стойности с помощта на метода „Fillna()“ на Pandas
Тази илюстрация демонстрира приложението на функцията Pandas “DataFrame.fillna()” за попълване на стойностите на NaN в дадения DataFrame с 0. Можете или да попълните липсващите стойности в една колона, или можете да ги попълните за целия DataFrame. Тук ще видим и двете техники.
За да приложим тези стратегии, трябва да получим подходяща платформа за изпълнение на програмата. И така, решихме да използваме инструмента „Spyder“. Започнахме нашия код на Python, като импортирахме инструментариума „pandas“ в програмата, защото трябва да използваме функцията Pandas, за да конструираме DataFrame, както и да попълним липсващите стойности в тази DataFrame. „pd“ се използва като псевдоним на „pandas“ в цялата програма.
Сега имаме достъп до функциите на Pandas. Първо използваме неговата функция „pd.DataFrame()“, за да генерираме нашия DataFrame. Извикахме този метод и го инициализирахме с три колони. Заглавията на тези колони са „M1“, „M2“ и „M3“. Стойностите в колоната „M1“ са „1“, „Няма“, „5“, „9“ и „3“. Записите в „M2“ са „Няма“, „3“, „8“, „4“ и „6“. Докато “M3” съхранява данните като “1”, “2”, “3”, “5” и “Няма”. Изискваме обект DataFrame, в който можем да съхраняваме този DataFrame, когато се извика методът „pd.DataFrame()“. Създадохме „липсващ“ DataFrame обект и го присвоихме чрез резултата, който получихме от функцията „pd.DataFrame()“. След това използвахме метода „print()“ на Python, за да покажем DataFrame на конзолата на Python.
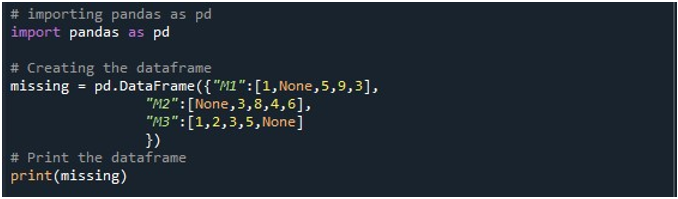
Когато изпълняваме тази част от кода, DataFrame с три колони може да се види на терминала. Тук можем да забележим, че и трите колони съдържат нулевите стойности в тях.
Създадохме DataFrame с някои нулеви стойности, за да приложим функцията „fillna()“ на Pandas, за да запълним липсващите стойности с 0. Нека научим как можем да направим това.
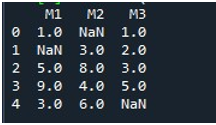
След показване на DataFrame, извикахме функцията „fillna()“ на Pandas. Тук ще се научим да попълваме липсващите стойности в една колона. Синтаксисът за това вече е споменат в началото на урока. Предоставихме името на DataFrame и посочихме заглавието на конкретната колона с функцията „.fillna()“. Между скобите на този метод предоставихме стойността, която ще бъде поставена на нулевите места. Името на DataFrame е „липсващо“ и колоната, която избрахме тук, е „M2“. Стойността, предоставена между скобите на „fillna()“ е „0“. И накрая, извикахме функцията „print()“, за да видите актуализирания DataFrame.

Тук можете да видите, че колоната „M2“ на DataFrame не съдържа никакви липсващи стойности сега, тъй като стойността на NaN е запълнена с 0.
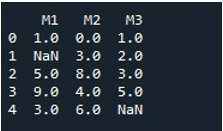
За да попълним NaN стойностите за цял DataFrame със същия метод, ние извикахме „fillna()“. Това е съвсем просто. Предоставихме името на DataFrame с функцията „fillna()“ и присвоихме стойността на функцията „0“ между скобите. И накрая, функцията “print()” ни показа попълнената DataFrame.

Това ни дава DataFrame без NaN стойности, тъй като всички стойности се запълват отново с 0 сега.
Пример 2: Попълване на NaN стойности с помощта на метода Pandas „Replace()“.
Тази част от статията демонстрира друг метод за попълване на NaN стойностите в DataFrame. Ще използваме функцията “replace()” на Pandas, за да попълним стойностите в една колона и в цял DataFrame.
Започваме да пишем кода в инструмента 'Spyder'. Първо импортирахме необходимите библиотеки. Тук заредихме библиотеката на Pandas, за да позволим на програмата Python да използва методите на Pandas. Втората библиотека, която заредихме, е NumPy и я наричаме „np“. NumPy обработва липсващите данни с метода “replace()”.
След това генерирахме DataFrame с три колони – „винт“, „пирон“ и „бормашина“. Стойностите във всяка колона са дадени съответно. Колоната „винт“ има стойности „112“, „234“, „Няма“ и „650“. Колоната „нокти“ има „123“, „145“, „Няма“ и „711“. И накрая, колоната „drill“ има стойности „312“, „Няма“, „500“ и „Няма“. DataFrame се съхранява в обекта DataFrame „инструмент“ и се показва с помощта на метода „print()“.
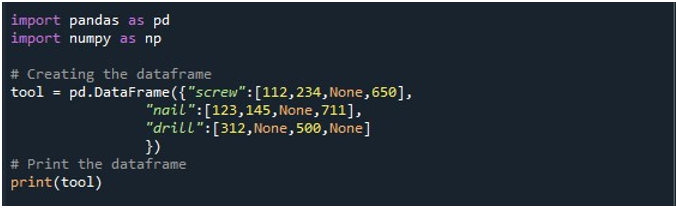
DataFrame с четири NaN стойности в записа може да се види в следното изходно изображение:
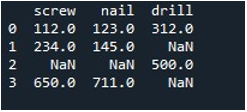
Сега използваме метода „replace()“ на Pandas, за да попълним нулевите стойности в една колона на DataFrame. За задачата извикахме функцията „replace()“. Доставихме името на DataFrame „инструмент“ и колоната „винт“ с метода „.replace()“. Между скобите задаваме стойността „0“ за записите „np.nan“ в DataFrame. Методът “print()” се използва за показване на изхода.

Полученият DataFrame ни показва първата колона с NaN записи, заменени с 0 в колоната „винт“.
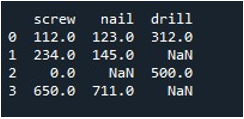
Сега ще се научим да попълваме стойностите в целия DataFrame. Извикахме метода „replace()“ с името на DataFrame и предоставихме стойността, която искаме да заменим с np.nan записи. Накрая отпечатахме актуализирания DataFrame с функцията “print()”.

Това ни дава резултантната DataFrame без липсващи записи.
Заключение
Справянето с липсващите записи в DataFrame е фундаментално и е необходимо изискване за намаляване на сложността и боравенето с данните предизвикателно в процеса на анализ на данни. Pandas ни предоставя няколко опции за справяне с този проблем. В това ръководство сме въвели две удобни стратегии. Ние прилагаме на практика и двете техники с помощта на инструмента „Spyder“, за да изпълним примерните кодове, за да направим нещата малко разбираеми и по-лесни за вас. Получаването на знания за тези функции ще изостри уменията ви за Pandas.