UTF-8 означава „ Unicode формат за трансформация 8-битов ” и съответства на страхотен формат за кодиране, който гарантира, че знаците се показват по подходящ начин на всички устройства, независимо от използвания език/скрипт. Освен това този формат е помощен за уеб страници и се използва за съхранение, обработка и предаване на текстови данни в интернет.
Този урок обхваща долупосочените области на съдържанието:
- Какво е UTF-8 кодиране?
- Как работи UTF-8 кодирането?
- Как се изчисляват стойностите на кодовите точки?
- Как да кодирам/декодирам UTF-8 в JavaScript?
- Кодирайте/декодирайте UTF-8 в JavaScript с помощта на методите „encodeURIComponent()“ и „decodeURIComponent()“.
- Кодирайте/декодирайте UTF-8 в JavaScript с помощта на методите „encodeURI()“ и „decodeURI()“.
- Кодирайте/декодирайте UTF-8 в JavaScript с помощта на регулярните изрази.
- Заключение
Какво е UTF-8 кодиране?
“ UTF-8 кодиране ” е процедурата за трансформиране на последователността от Unicode знаци в кодиран низ, състоящ се от 8-битови байта. Това кодиране може да представлява голям диапазон от знаци в сравнение с другите кодировки на знаци.
Как работи UTF-8 кодирането?
Докато представя знаци в UTF-8, всяка отделна кодова точка е представена от един или повече байта. Следва разбивка на кодовите точки в диапазона ASCII:
- Един байт представлява кодовите точки в ASCII диапазона (0-127).
- Два байта представляват кодовите точки в ASCII диапазона (128-2047).
- Три байта представляват кодовите точки в диапазона ASCII (2048-65535).
- Четири байта представляват кодовите точки в диапазона ASCII (65536-1114111).
Това е така, че първият байт на „ UTF-8 последователност се нарича „ водещ байт ”, който дава информация за броя на байтовете в последователността и стойността на кодовата точка на символа.
„Водещият байт“ за последователност от един, два, три и четири байта е съответно в диапазона (0-127), (194-233), (224-239) и (240-247).
Останалите байтове в последователността се наричат „ изоставащ ” байта. Всички байтове за последователност от два, три и четири байта са в диапазона (128-191). Това е така, че стойността на кодовата точка на символа може да бъде изчислена чрез анализиране на водещите и крайните байтове.
Как се изчисляват стойностите на кодовите точки?
Стойностите на кодовите точки за различни поредици от байтове се изчисляват, както следва:
- Двубайтова последователност: Кодовата точка е еквивалентна на „((lb – 194) * 64) + (tb – 128)“.
- Трибайтова последователност : Кодовата точка е еквивалентна на „((lb – 224) * 4096) + ((tb1 – 128) * 64) + (tb2 – 128)“.
- Четири-байтова последователност : Кодовата точка е еквивалентна на „((lb – 240) * 262144) + ((tb1 – 128) * 4096) + ((tb2 – 128) * 64) + (tb3 – 128)“.
Как да кодирам/декодирам UTF-8 в JavaScript?
Кодирането и декодирането на UTF-8 в JavaScript може да се извърши чрез посочените по-долу подходи:
- “ enodeURIComponent() ' и ' decodeURIComponent() ” Методи.
- “ кодиранеURI() ' и ' decodeURI() ” Методи.
- Регулярни изрази.
Подход 1: Кодиране/декодиране на UTF-8 в JavaScript с помощта на методите „encodeURIComponent()“ и „decodeURIComponent()“
„ encodeURIComponent() ” кодира URI компонент. Освен това може да кодира специални символи като @, &, :, +, $, # и др. decodeURIComponent() ”, обаче, декодира URI компонент. Тези методи могат да се използват съответно за кодиране и декодиране на предадените стойности в UTF-8.
Синтаксис (метод „encodeURIComponent()“)
encodeURIComponent ( х )В дадения синтаксис „ х ” показва URI, който трябва да бъде кодиран.
Върната стойност
Този метод извлече кодиран URI като низ.
Синтаксис (метод „decodeURIComponent()“)
decodeURIComponent ( х )Тук, ' х ” се отнася до URI, който трябва да бъде декодиран.
Върната стойност
Този метод дава декодирания URI.
Пример 1: Кодиране на UTF-8 в JavaScript
Този пример кодира предадения низ до кодирана UTF-8 стойност с помощта на дефинирана от потребителя функция:
връщане unescape ( encodeURIComponent ( х ) ) ;
}
нека вал = 'тук' ;
конзола. дневник ( „Дадена стойност ->“ + вал ) ;
нека encodeVal = кодиране_utf8 ( вал ) ;
конзола. дневник ( 'Кодирана стойност -> ' + encodeVal ) ;
В тези кодови редове изпълнете дадените по-долу стъпки:
- Първо, дефинирайте функцията ' encode_utf8() ”, който кодира предадения низ, представен от посочения параметър.
- Това кодиране се извършва от „ encodeURIComponent() ” в дефиницията на функцията.
- Забележка: „ изключване () ” методът замества всяка последователност за избягване със символа, представен от нея.
- След това инициализирайте стойността, която ще бъде кодирана, и я покажете.
- Сега извикайте дефинираната функция и предайте дефинираната комбинация от знаци като нейни аргументи, за да кодирате тази стойност в UTF-8.
Изход
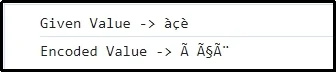
Тук може да се подразбира, че отделните знаци са представени и кодирани съответно в UTF-8.
Пример 2: Декодиране на UTF-8 в JavaScript
Демонстрацията на код по-долу декодира предадената стойност (под формата на знаци) до кодирано UTF-8 представяне:
връщане decodeURIComponent ( бягство ( х ) ) ;
}
нека вал = 'à çè' ;
конзола. дневник ( „Дадена стойност ->“ + вал ) ;
нека декодира = decode_utf8 ( вал ) ;
конзола. дневник ( 'Декодирана стойност -> ' + декодирам ) ;
В този блок код:
- По същия начин дефинирайте функцията „ decode_utf8() ”, който декодира предадената комбинация от знаци чрез „ decodeURIComponent() ” метод.
- Забележка: „ бягство() ” метод извлича нов низ, в който различни знаци са заменени с шестнадесетични последователности за избягване.
- След това посочете комбинацията от знаци за декодиране и достъп до дефинираната функция, за да извършите декодирането в UTF-8 по подходящ начин.
Изход

Тук може да се подразбира, че кодираната стойност в предишния пример е декодирана до стойността по подразбиране.
Подход 2: Кодиране/декодиране на UTF-8 в JavaScript с помощта на методите „encodeURI()“ и „decodeURI()“
„ кодиранеURI() ” кодира URI чрез заместване на всеки екземпляр от множество символи с редица последователности за избягване, представляващи UTF-8 кодирането на знака. В сравнение с „ encodeURIComponent() ”, този конкретен метод кодира ограничени знаци.
„ decodeURI() ” метод обаче декодира URI (кодиран). Тези методи могат да бъдат приложени в комбинация за кодиране и декодиране на комбинацията от знаци в UTF-8 кодирана стойност.
Синтаксис (encodeURI() Метод)
encodeURI ( х )В горния синтаксис „ х ” съответства на стойността, която трябва да бъде кодирана като URI.
Върната стойност
Този метод извлича кодираната стойност под формата на низ.
Синтаксис (decodeURI() Метод)
decodeURI ( х )Тук, ' х ” представлява кодираният URI, който трябва да бъде декодиран.
Върната стойност
Той връща декодирания URI като низ.
Пример 1: Кодиране на UTF-8 в JavaScript
Тази демонстрация кодира предадената комбинация от знаци в кодирана UTF-8 стойност:
връщане unescape ( encodeURI ( х ) ) ;
}
нека вал = 'тук' ;
конзола. дневник ( „Дадена стойност ->“ + вал ) ;
нека encodeVal = кодиране_utf8 ( вал ) ;
конзола. дневник ( 'Кодирана стойност -> ' + encodeVal ) ;
Тук си припомнете подходите за дефиниране на функция, разпределена за кодиране. Сега приложете метода „encodeURI()“, за да представите предадената комбинация от знаци като UTF-8 кодиран низ. След това по същия начин дефинирайте символите, които да бъдат оценени, и извикайте дефинираната функция, като предадете дефинираната стойност като нейни аргументи, за да извършите кодирането.
Изход
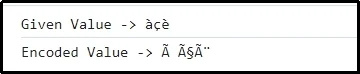
Тук е очевидно, че предадената комбинация от знаци е кодирана успешно.
Пример 2: Декодиране на UTF-8 в JavaScript
Демонстрацията на код по-долу декодира кодираната UTF-8 стойност (в предишния пример):
връщане decodeURI ( бягство ( х ) ) ;
}
нека вал = 'à çè' ;
конзола. дневник ( „Дадена стойност ->“ + вал ) ;
нека декодира = decode_utf8 ( вал ) ;
конзола. дневник ( 'Декодирана стойност -> ' + декодирам ) ;
Съгласно този код декларирайте функцията „ decode_utf8() ”, който съдържа посочения параметър, който представлява комбинацията от знаци, които трябва да бъдат декодирани с помощта на „ decodeURI() ” метод. Сега посочете стойността за декодиране и извикайте дефинираната функция, за да приложите декодирането към „ UTF-8 ” представителство.
Изход
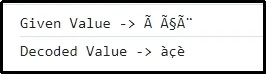
Този резултат предполага, че кодираната стойност преди това е решена съответно.
Подход 3: Кодиране/декодиране на UTF-8 в JavaScript с помощта на регулярните изрази
Този подход прилага кодирането така, че многобайтовият Unicode низ е кодиран в UTF-8 множество еднобайтови знаци. По същия начин декодирането се извършва така, че кодираният низ се декодира обратно до многобайтови Unicode символи.
Пример 1: Кодиране на UTF-8 в JavaScript
Кодът по-долу кодира многобайтовия Unicode низ в UTF-8 еднобайтови знаци:
ако ( тип вал != 'низ' ) хвърлям нов TypeError ( „Параметърът“ вал 'не е низ' ) ;
конст низ_utf8 = вал. замени (
/[\u0080-\u07ff]/g , // U+0080 - U+07FF => 2 байта 110yyyyy, 10zzzzzz
функция ( х ) {
беше навън = х. charCodeAt ( 0 ) ;
връщане низ . fromCharCode ( 0xc0 | навън >> 6 , 0x80 | навън и 0x3f ) ; }
) . замени (
/[\u0800-\uffff]/g , // U+0800 - U+FFFF => 3 байта 1110xxxx, 10yyyyyy, 10zzzzzz
функция ( х ) {
беше навън = х. charCodeAt ( 0 ) ;
връщане низ . fromCharCode ( 0xe0 | навън >> 12 , 0x80 | навън >> 6 и 0x3F , 0x80 | навън и 0x3f ) ; }
) ;
конзола. дневник ( 'Кодирана стойност с помощта на регулярен израз -> ' + низ_utf8 ) ;
}
кодира UTF8 ( 'тук' )
В този фрагмент от код:
- Дефинирайте функцията ' кодиранеUTF8() “, съдържащ параметъра, който представлява стойността, която трябва да бъде кодирана като „ UTF-8 ”.
- В неговата дефиниция приложете проверка на предадената стойност, която не е низът, като използвате „ тип ” и връща указаното персонализирано изключение чрез „ хвърлям ” ключова дума.
- След това приложете „ charCodeAt() ' и ' fromCharCode() ” методи за извличане на Unicode на първия знак в низа и преобразуване на дадената Unicode стойност съответно в знаци.
- И накрая, извикайте дефинираната функция чрез предаване на дадена последователност от знаци, за да кодирате тази стойност като „ UTF-8 ” представителство.
Изход

Този изход означава, че кодирането е извършено правилно.
Пример 2: Декодиране на UTF-8 в JavaScript
В тази демонстрация последователността от знаци се декодира до „ UTF-8 ” представителство:
ако ( тип вал != 'низ' ) хвърлям нов TypeError ( „Параметърът“ вал 'не е низ' ) ;
конст ул = вал. замени (
/[\u00e0-\u00ef][\u0080-\u00bf][\u0080-\u00bf]/g ,
функция ( х ) {
беше навън = ( ( х. charCodeAt ( 0 ) и 0x0f ) << 12 ) | ( ( х. charCodeAt ( 1 ) и 0x3f ) << 6 ) | ( х. charCodeAt ( 2 ) и 0x3f ) ;
връщане низ . fromCharCode ( навън ) ; }
) . замени (
/[\u00c0-\u00df][\u0080-\u00bf]/g ,
функция ( х ) {
беше навън = ( х. charCodeAt ( 0 ) и 0x1f ) < '+str);
}
декодиранеUTF8('à çè')
В този код:
- По същия начин дефинирайте функцията „ декодиранеUTF8() ” с параметър, който се отнася до предадената стойност, която трябва да бъде декодирана.
- В дефиницията на функцията проверете за условието на низа на предадената стойност чрез „ тип ' оператор.
- Сега приложете „ charCodeAt() ” за извличане на Unicode съответно на първия, втория и третия знак от низа.
- Също така приложете „ String.fromCharCode() ” за трансформиране на Unicode стойностите в знаци.
- По същия начин повторете тази процедура отново, за да извлечете Unicode на първия и втория символ от низа и да трансформирате тези unicode стойности в знаци.
- И накрая, отворете дефинираната функция, за да върнете декодираната UTF-8 стойност.
Изход

Тук може да се провери дали декодирането е извършено правилно.
Заключение
Кодирането/декодирането в UTF-8 представяне може да се извърши чрез „ enodeURIComponent()” и ' decodeURIComponent() методи, „ кодиранеURI() ' и ' decodeURI() ” или с помощта на регулярните изрази.